axi
AXI笔记 [TOC]
AXI 自定义指令
MCU配置ACC的两种方式
- 通过MCU直接配置加速器的配置寄存器:
- MCU从Config Memory读取配置信息
- MCU将配置信息写入到加速器内部的配置寄存器
- MCU通过自定义指令:
- 自定义指令用于配置ACC的DMA控制器
- 每一个ACC都有一个DMA
- 从配置加速器寄存器的角度来看,DMA的效率更高、但是不够灵活
- MCU用于配置ACC内部的DMA,增加DMA的灵活性
- DMA搬运数据的起始地址
- DMA搬运开始信号
- 通过软件来执行自定义指令: 控制DMA -> 配置ACC
- 对比LW指令没有明显的提升
- 自定义指令用于配置ACC的DMA控制器
加速器配置自定义指令集
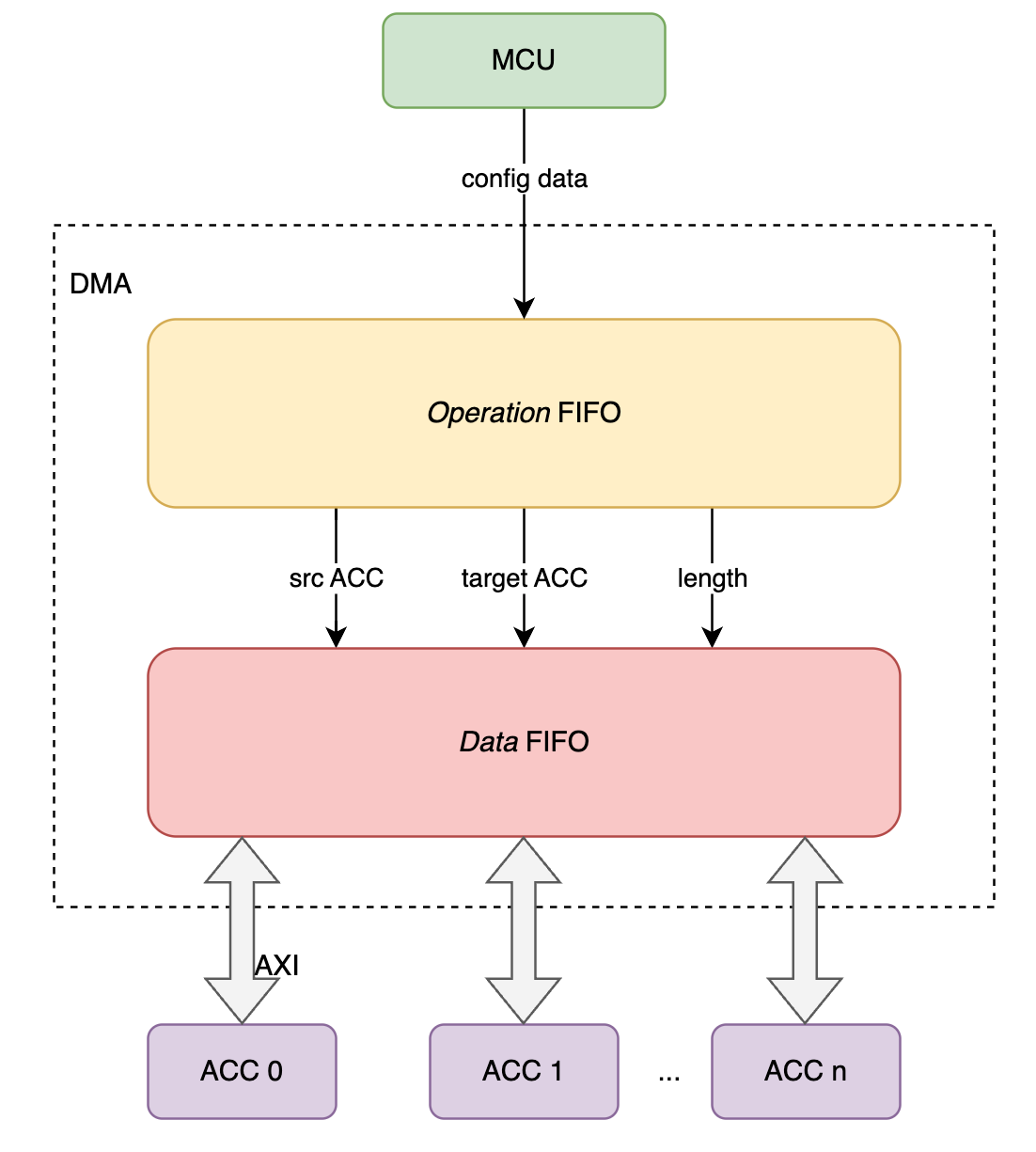
硬件支持
- 修改MCU ID以译码该自定义指令
- 在MCU增加DMA模块(可以看作是MCU的协处理器)
- DMA模块内部支持Operation FIFO用于存储所有的DMA操作(避免MCU Stall)
- Operation Format
- Length: 24 bits
- Acc1: 4 bits
- Acc2: 4 bits
软件支持
寻找可以自定义的编码空间

- 上图展示了目前RISC-V的opcode字段的占用情况
- custom-0,
custom-1是官方推荐的自定义的编码空间,因此我们自定义执行的opcode采用custom-0编码,为
0x0010111
自定义指令格式
- 确定了opcode之后,还需要确定指令的编码格式,RISC-V一共有6种编码格式

- 根据我们对该自定义指令的使用需求来确定编码格式:
U-Type是最适合的,但是U-Type在C程序里使用的时候不方便R-Type在C程序里使用是最方便的
- 确定了opcode之后,还需要确定指令的编码格式,RISC-V一共有6种编码格式
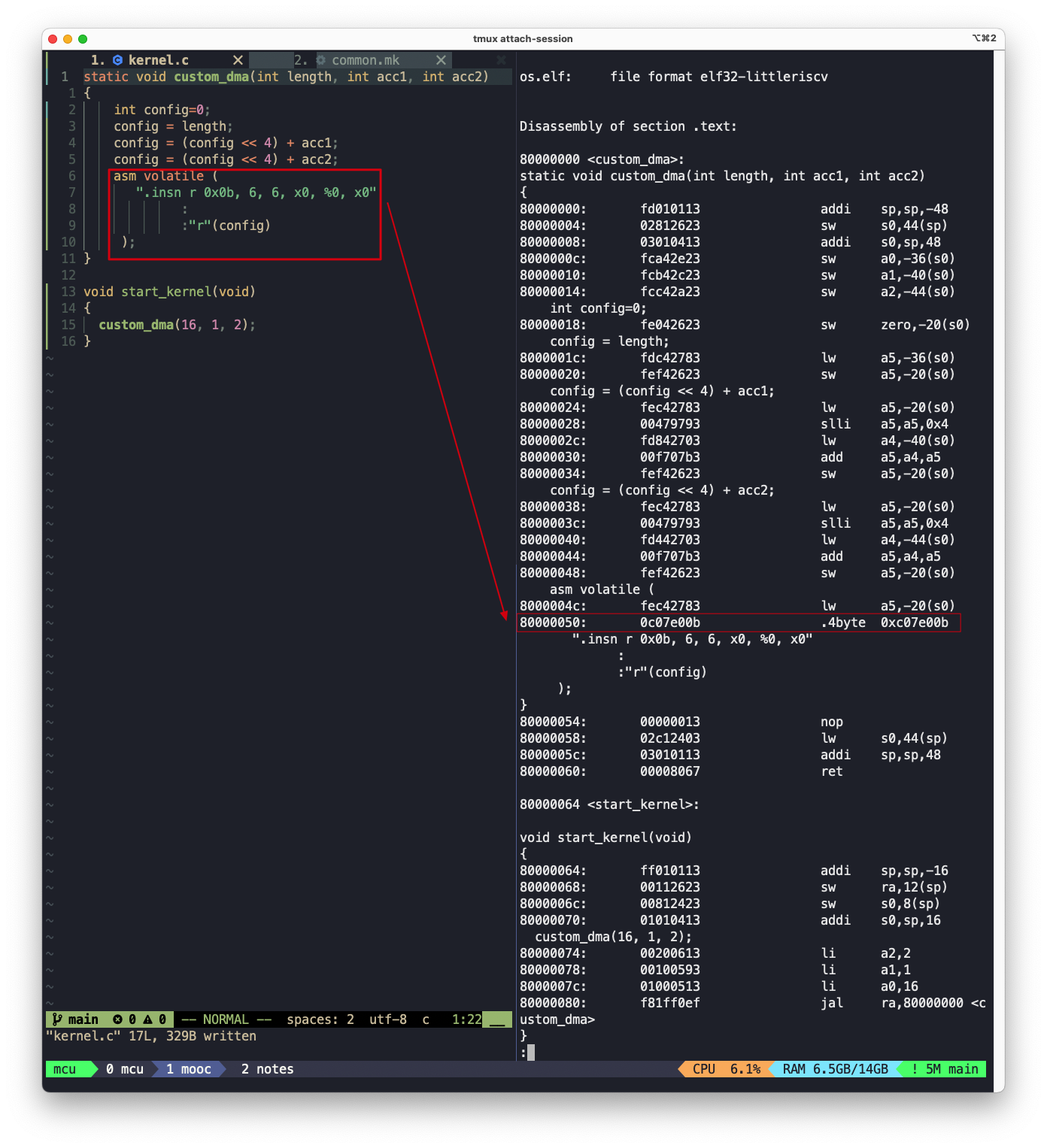
支持自定义指令集采用内联汇编的方法,具体有如下两种:
- 利用.insn模板进行编程,该网页展示了各种类型的RISC-V指令的insn编码格式

- 修改
binutils让riscv gcc认识到这条指令
- 利用.insn模板进行编程,该网页展示了各种类型的RISC-V指令的insn编码格式
在c程序中使用该自定义令
====================================== 分割线 ============================================
AXI Master类型
- 多个Slave访问:arbiter, buffer
- Out of Order: ID
- Outstanding transaction
- multi-clock domain for low power
- stall the pipeline before finish transaction
- register slice to pipeline: make this a TODO as I don't fully understand AXI pipeline
method 1
- ACC serves as AXI slave, DMA serves as AXI master, DRAM serves as AXI slave
- every time ACC needs write/read to SDRAM, CPU triggers the DMA to pass the data from/to ACC
- bad:
- every transaction need CPU
- it sucks when ACC need small amount of data very often, CPU has to trigger DMA very often
method 2
- ACC create the write/read request and stores the request in a FIFO
- the DMA can read from the FIFO and do the data transaction if there is a request
- bad:
- transaction TIMING issue
- another hardware which watch the FIFO to see if there is a transaction needed
method 3
- ACC serves as AXI master, and direction write/read to DRAM
- ways to do this:
- write RTL of AXI in your ACC
- use IP of AXI in your ACC
- use Vivado HLS in your ACC
4种AXI Master类型
- single beat
- single beat pipelined
- bursting, single channel
- bursting, multiple channel
single beat
- 特点:burst size等于0,给出地址及控制信号后只包含一次数据传输,传输完成之后再发送下一次地址跟控制信号
- 实现:
- AxLEN=0
- WLAST=1, ignore RLAST
- ignore AxBURST:不需要关注burst类型,也不需要关心burst地址是否跨越4kB边界
- 优点:功能上是可用的
- 缺点带宽(throughput)很低: data bus利用率很低,基本上都是空cycle

single beat pipelined
- 特点支持outstanding传输:传输反馈(response)没有收到之前就可以发送下一次传输的地址跟控制信号
- 实现:
- issue状态机
- response状态机
- 同步状态机
- counter & FIFO用于记录request,并且在收到response的时候使用
- AxID是常量:保证所有传输是顺序的
- 优点: data bus带宽理论上可以吃满
- 缺点:
对Slave要求过于理想(要求slave的两个burst传输之间没有空闲);
eg: Xilinx’s AXI block RAM interface每次burst传输需要3+N个cycle,若N=0,则带宽利用率为25% - 适用场景:传输地址不是连续(访问image的列数据)、或者下次传输地址未知的场景
bursting, single channel
- 特点:支持burst传输(一次地址&控制信号,多次data传输)
- 实现:
- 记录当前已经传输的beats数
- WLAST在最后一次写的时候拉高
- 地址:
- wrap & fixed, beats <= 16; increment, beats <= 256
- 地址不能跨越4kB: 通过配置AxLEN保证
- PS: 尽可能在一次burst传输中传输尽可能多的beats
bursting, multiple channel
特点: 通过ID实现乱序传输:
- outstanding but in order 读写:
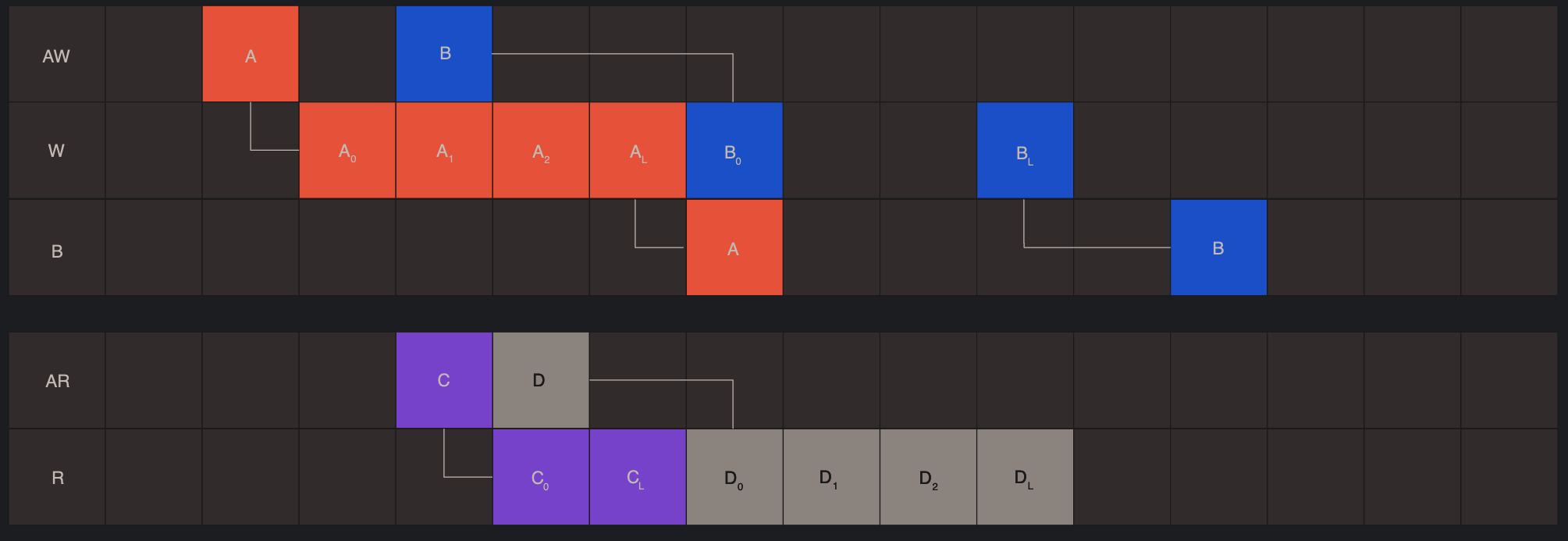
- OoO写:不同ID的写传输,其Response可以乱序,但是Wdata不能interleaving
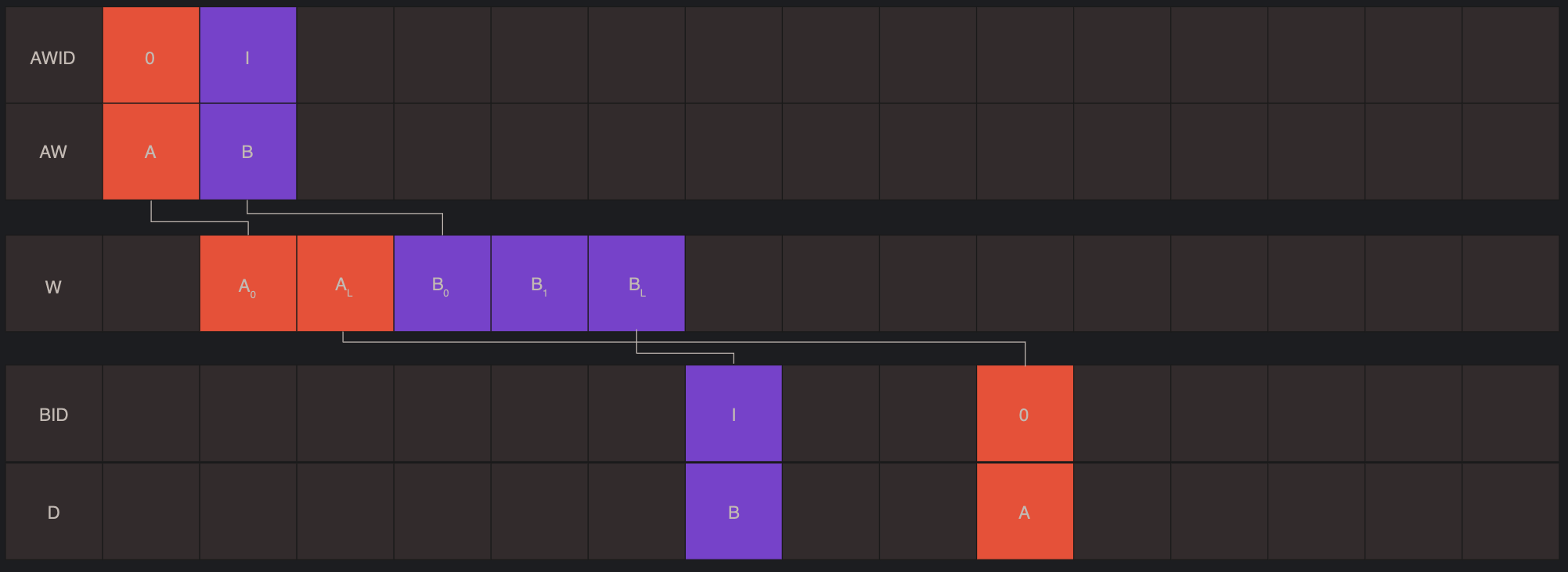
- OoO读:不同ID的读传输,其Rdata可以interleaving

- outstanding but in order 读写:
实现:
- master需要支持reorder buffer
优点: 适用于一个Master需要同时访问多个slave的场景
缺点: 对AXI Interconnect要求比较高,master可以并行访问slaves时才好用
MCU设计方案
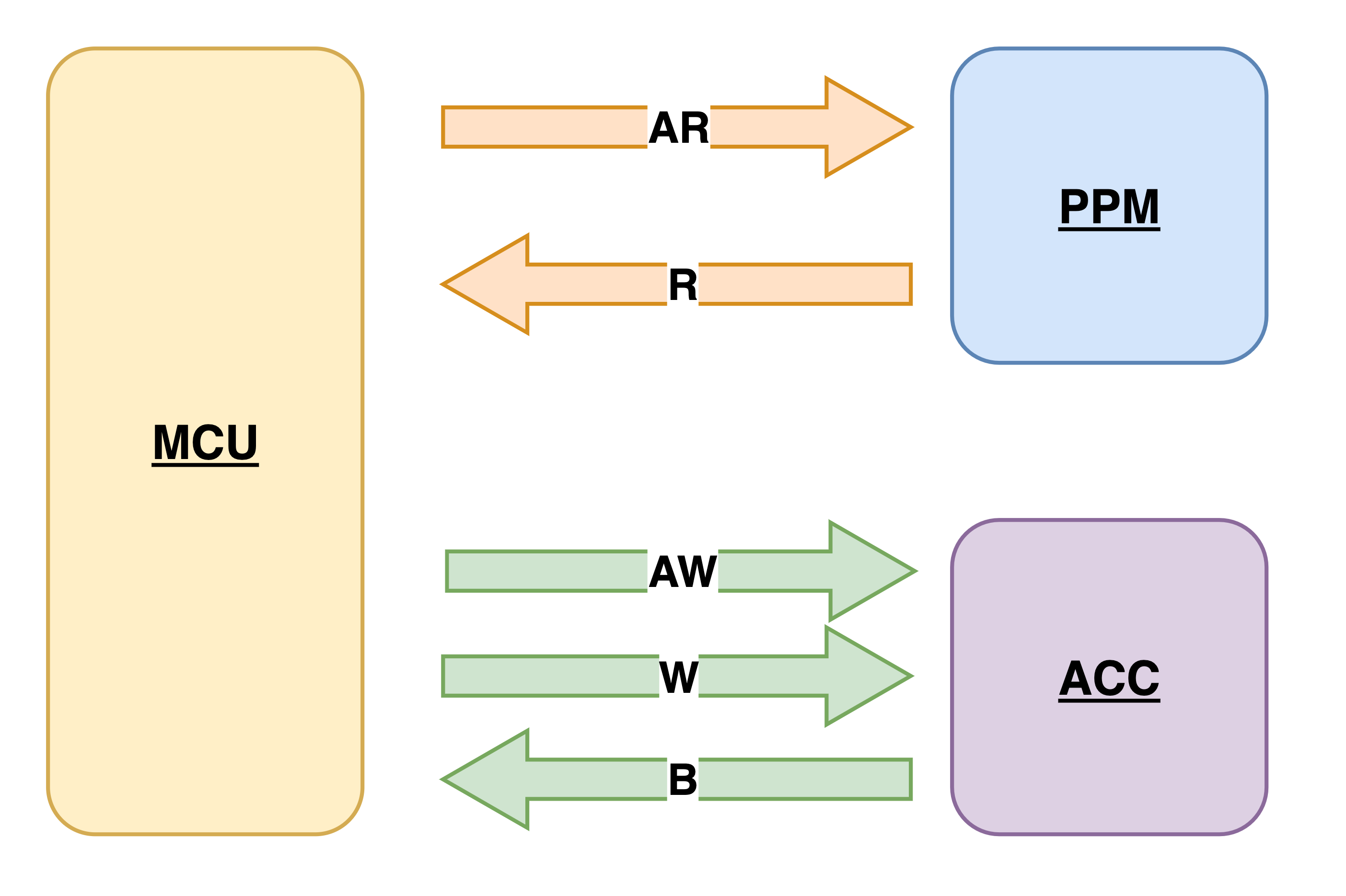
单发射流水线MCU集成AXI需要的场景
- 写到ACC的时候,由于地址不保证连续,所以不能采用burst写
- 从PPM(ping pong memory)读的时候,地址是连续的,可以采用burst读
什么场景下会触发AXI Burst传输
- 对于顺序处理器核而言,每个cycle至多有一条riscv load指令
- 访问PPM的延迟比访问D-Memory的延迟高
- 配置ACC的指令流:
- 情形1
1
2
3
4
5load rd, PPM[addr]
store rd, ACC[addr]
...
load rd, PPM[addr]
store rd, ACC[addr] - 情形2 > PS: 从PPM read指令后面,还需要对read的数据进行解析得到addr跟data,才可以写入到ACC
1
2
3
4
5load rd, PPM[addr]
load rd, PPM[addr]
...
store rd, ACC[addr]
store rd, ACC[addr]
- 情形1
- burst传输的场景:
- 通过burst读,顺序地读取多个地址的数据(预读取)
- Optional: read操作不会stall流水线
顺序单发射处理器核如何支持burst传输
- 需要在MCU跟AXI Channel之间增加AXI Master Interface
- Interface用于:
- 支持read burst
- 避免burst传输时MCU stall
- 支持write pipeline
- 解决MCU跟ACC、PPM之间的跨时钟域问题
哪条指令会触发burst传输
- CORTEX-A9有ldm/stm(load multiple, store multiple)指令来触发AXI burst操作
- MCU可以根据load指令&地址范围处于PPM来触发burst
read,
burst length=16 - 增加自定义指令来支持对PPM的burst读:
- 修改decoder
- 修改编译器
- 灵活
burst传输时MCU是否会Stall
- 处理器是否支持Out-of-Order
- 指令之间的相关性
- AXI Interface设计
write to ACC流水
- MCU执行Store指令,Store的地址范围属于ACC的地址空间
- MCU执行到MEM Stage的时候,会判断地址范围,不会写入到D-Memory,而是通过AXI写通道写到ACC
MCU AXI的设计总结
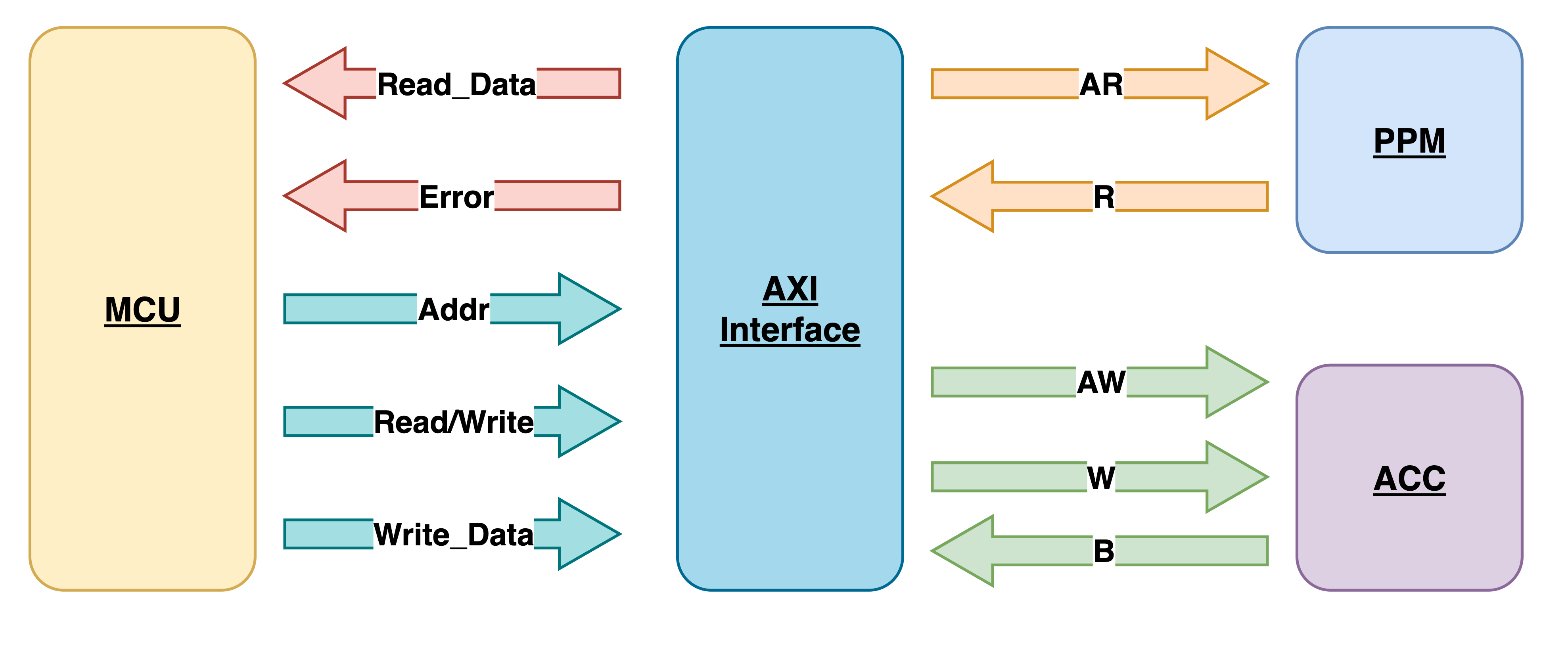
采用burst对PPM进行读取:
- 当地址空间对应PPM时,Interface会对PPM发起16个beat的Burst读
- 读回的data会被存放在Interface的异步
Read_FIFO中 - FIFO头元素的地址跟MCU的read addr相时,FIFO头部元素pop
采用pipeline的方式对ACC进行写:
- AXI Interface接收MCU发的write addr, write data, write control等信号
- 写的时候不用收到ACC的反馈即可发起下一笔写
- Interface若收到AXI Slave的Error信号,会发送给MCU,触发Exception
Interface跟Slave之间采用1主多从的拓扑结构:
- 有译码器根据地址选择slave
- 没有仲裁器