超标量处理器设计
超标量处理器设计笔记
基础知识
为什么需要超标量处理器:
\(time=指令数*CPI*周期\)
CPI:IPC的倒数,我们想要IPC越搞越好,采用单发射流水线架构,最高可以得到的
IPC=1如果想要
IPC>1有如下两种方法:- 超标量处理器:硬件支持; CPU
- VLIW:编译器、程序员;DSP
周期:频率的倒数,我们想要频率越高越好
频率跟IPC是不能兼得的,二者之间有很多tradoff
理想的流水线:
- 各级流水线时间一样长(CISC不要实现,RISC好实现)
- 各级流水线上的功能部件,被所有指令都复用
- 流水线各级之间不存在依赖(制约流水线性能的关键)
- 将5级流水线和成3级流水线->低功耗处理器
- 高性能处理器: 将5级流水线拆分,有如下的代价(无限拆分流水线并不可行):
- 更复杂的控制逻辑
- 更多的流水线寄存器
- I\(、D\)端口数增加
- 面积、寄存器增加、频率增加导致功耗增加
- 更大的分支预测错误代
指令相关性(严重影响指令之间的乱序执行):
- RAW:不可避免,可以用bypass解决
- WAW,WAR:乱序处理器可以通过寄存器重命名避免;顺序处理器自动解决了这两种
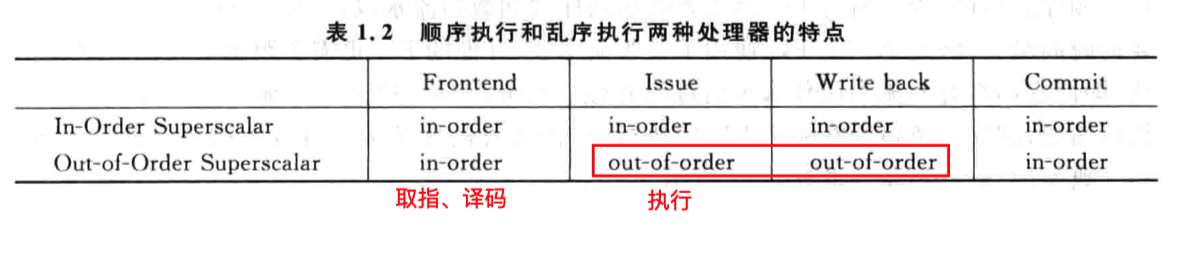
超标量处理器:
- 定义:一次可以取出、处理“超过一条指令”的处理器
- 分类:顺序、乱序(在执行、写回部分乱序);乱序主要指指令可以乱序地进入到FU(functional
unit)中被处理
- 顺序处理器在issue的时候,需要使用scoreboard来记录,详见《超标量处理器》P10;
不同的执行单元,有同样的流水线级数(导致简单的操作被拉的跟复杂的操作一样)
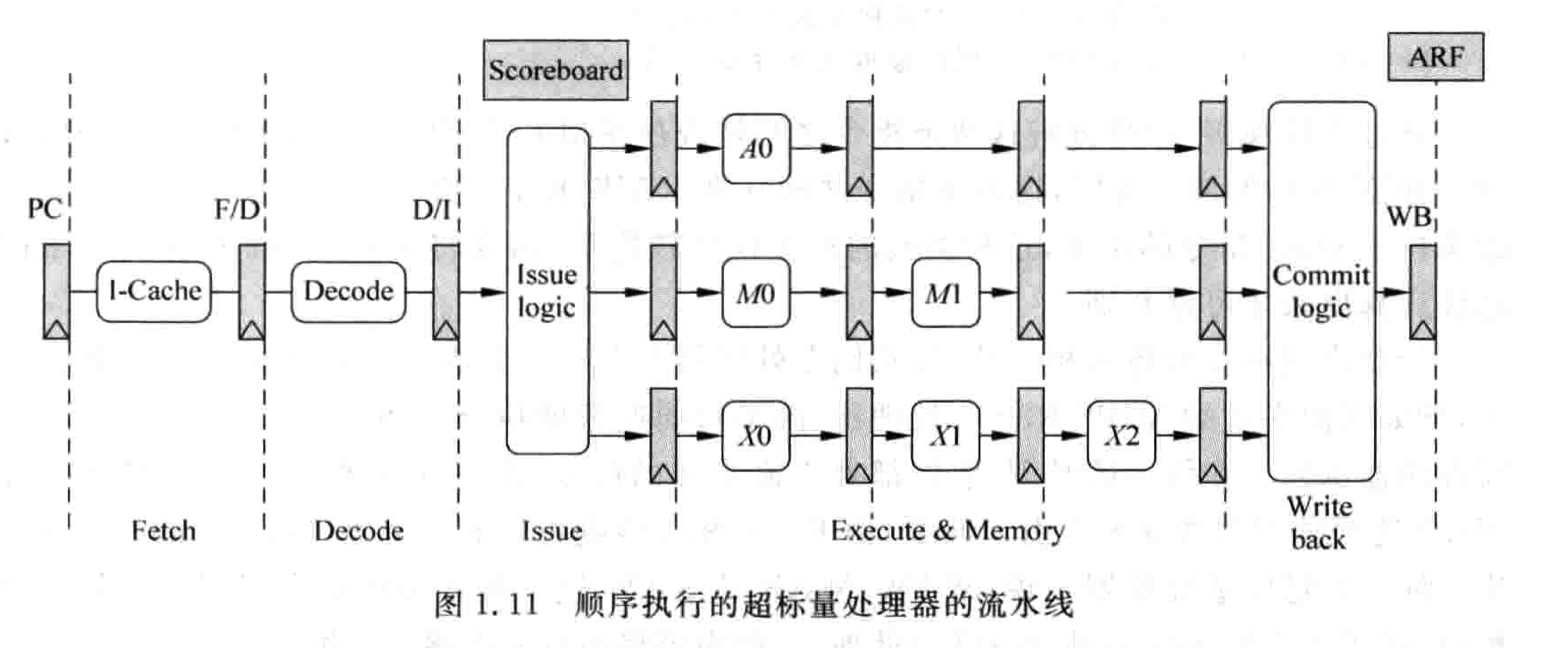 如果不满足issue的条件,则指令会一直等待在ID Stage
如果不满足issue的条件,则指令会一直等待在ID Stage 
- 乱序处理器:操作数准备就序、运算单元空闲的时候,指令不用在傻傻地等待顺序执行了,可以插队执行
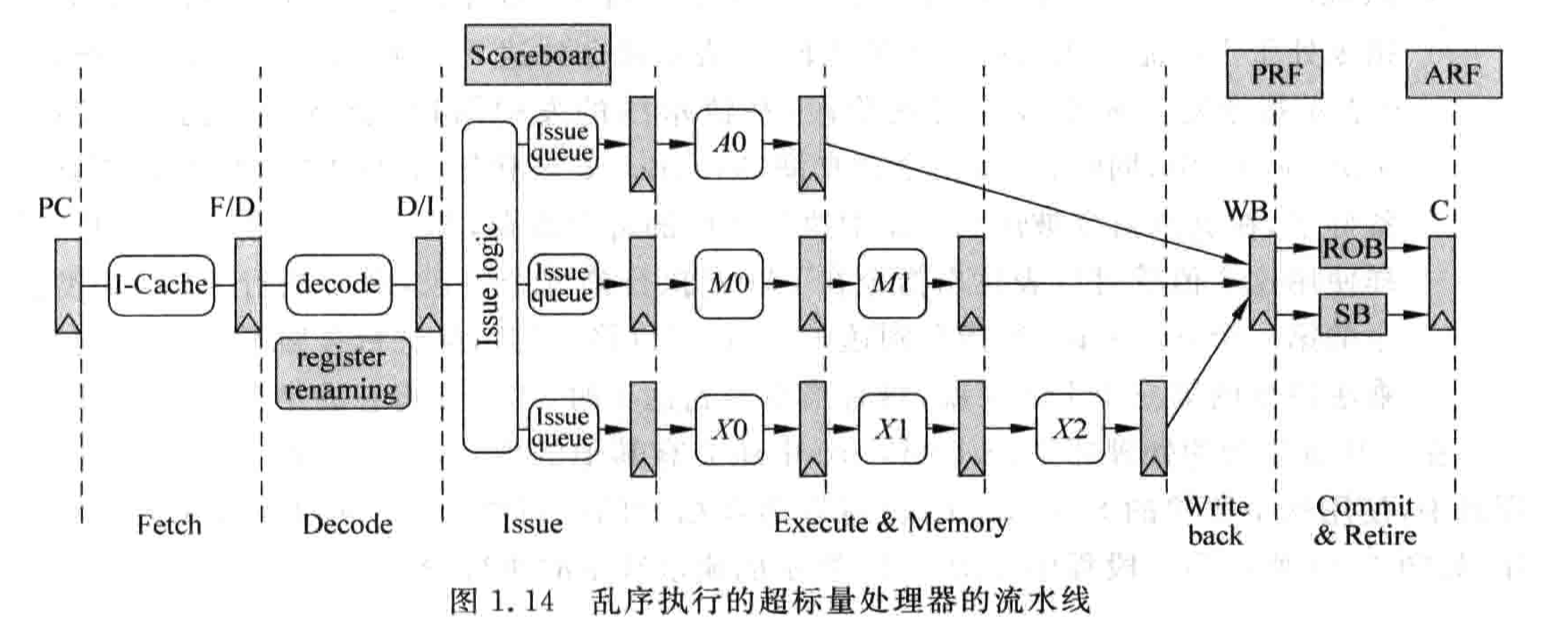
- renaming: 解决WRW,WRA相关性:
- 维护ARF(archtecture register file)跟PRF(physical register file)的映射关系
- 维护空闲的PRF
- 维护寄存器之间的RAW相关性,后续通过bypass来解决
- dispatch:将重命名之后的指令,分发到各个IQ, ROB, SB中; 如果没有空余位置,则会阻塞所有的rename stage及之前的所有stage
- IQ(issue queue): 在Issue Stage,各个指令流会在IQ里等待操作数准备就序
- ROB(reorder buffer):保证指令的按序提交,在dispatch的时候,指令被顺序地写入到ROB; 保证顺序执行、保证精确异常
- SB(store
buffer):store指令必须在提交的时候才将结果写入到D-memory,在此之前结果存储在SB中;
引入了SB之后,load指令需要同时从D-memory跟SB中读取数据

- WB:将FU的计算结果写入到PRF,已经通过bypass传递给所有的FU(FU通过选择电路选择合适的bypass数据); Bypass电路会严重影响频率,因为bypass的布线很多,布线的延迟甚至可能超过门电路的延迟 (可以通过cluster结构来处理连线延时过长的问题)
- 恢复电路:如上所述, 在乱序超标量处理器中有很多的存储部件,当一条指令执行错误、异常发生等情况出现的时候, 都需要将上述存储部件的状态进行恢复<-乱序超标量处理器的恢复电路,也是很复杂的设计点
- renaming: 解决WRW,WRA相关性: