innovation
论文的创新点
低功耗方面的设计
- wfi进入低功耗模式: wfi
通知处理器目前没有任何有用的工作,所有它应该进入低功耗模式,
直到任何使能有效的中断等待处理,即
mie&mi p ≠ 0。RISC-V 处理器以多种方式实现 该指令,包括到中断待处理之前都停止时钟 > 如果在全局中断使能有效(mstatus.MIE = 1)时执行 wfi,然后有一个使能有效的中断等 待执行,则处理器跳转到异常处理程序。另一方面,如果在全局禁用中断时执行 wfi,接着 一个使能有效的中断等待执行,那么处理器继续执行 wfi 之后的代码。这些代码通常会检 查控制状态寄存器 mip,以决定下一步该做什么。与跳转到异常处理程序相比,这个策略可 以减少中断延迟,因为不需要保存和恢复整数寄存器。
取指方面的设计
- IF FIFO处理压缩指令
中断方面的设计
中断尾链、中断嵌套
mtvec两种配置方式(向量、非向量J)
非向量模式
可以配置向量模式跟非向量模式,向量模式下中断响应最快
非向量模式下(参考该文章5.13): - mtvt2[0]==0: 中断跟异常都通过mtvec指定地址 - mtvt2[0]==1: 中断通过mtvt2指定地址
由于非向量处理模式时处理器在跳到中断服务程序之前需要先执行一段共有的软件代码进行上下文的保存,因此,从中断源拉高到处理器开始执行中断服务程序中的第一条指令,需要经历以下几个方面的时钟周期开销:
- 处理器内核响应中断后进行跳转的开销。理想情况下约4个时钟周期。
- 处理器内核保存CSR寄存器mepc、mcause、msubm入堆栈的开销。
- 处理器内核保存上下文所花费的周期开销。如果是RV32E的架构,则需要保存8个通用寄存器,如果是RV32I的架构,则需要保存16个通用寄存器
- 处理器内核跳转到中断服务程序(Interrupt Service Routine,ISR)中去的开销。理想情况下约需要5个时钟周期。
对于非向量处理模式的中断而言,由于在跳入和退出中断服务程序之前,处理器要进行上下文的保存和恢复,因此进行“中断咬尾”能够节省显著的时间(节省一次背靠背的保存上下文和恢复上下文)。
中断咬尾(尾链):
- 效果:避免了一次背靠背的保存上下文操作
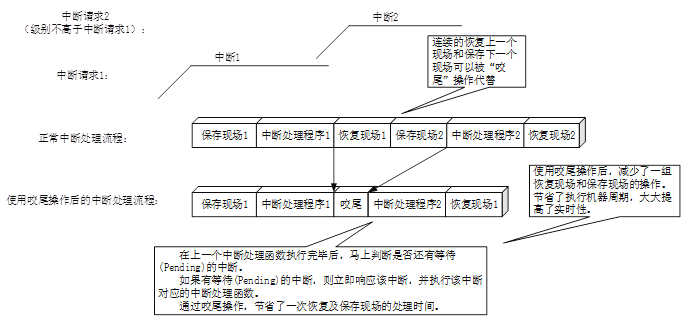
- 正常中断处理流程: 保存上下文->ISR->恢复上下文
- 支持中断咬尾:保存上下文->ISR1->ISR2->...->恢复上下文
- 其实现的原理在于: ISR结束之后,会判断是否有别的中断在Pending,如果有则直接进入到对应的ISR处理
- 效果:避免了一次背靠背的保存上下文操作
向量模式
- 向量处理模式时处理器会直接跳到中断服务程序,并没有进行上下文的保存,因此,中断响应延迟非常之短,从中断源拉高到处理器开始执行中断服务程序中的第一条指令,基本上只需要硬件进行查表和跳转的时间开销,理想情况下约6个时钟周期。
- 对于向量处理模式的中断服务程序函数,一定要使用特殊的attribute((interrupt))来修饰中断服务程序函数(使用了特殊的attribute((interrupt))来修饰该中断服务程序函数,那么编译器会自动的进行判断,当编译器发现该函数调用了其他子函数时,便会自动的插入一段代码进行上下文的保存)。
- 向量处理模式时,由于在跳入中断服务程序之前,处理器并没有进行上下文的保存,因此,理论上中断服务程序函数本身不能够进行子函数的调用(即,必须是Leaf Function)。
取指Ping Pong FIFO设计
问题描述
IF Stage的FIFO在遇到指令重定向到时候,会导致冲刷掉其内部所有的预取指令,是很大的浪费

由于FIFO容量是5*16,当所有指令都是压缩指令的时候,指令的冲刷会导致至多4条有效指令被浪费了
单一FIFO的重定向逻辑如下:

- cycle0发生重定向
- cycle1冲刷掉FIFO里所有的指令,并且从I-Memory里按照sequential_pc取出指令放到FIFO头部(该指令在流水线上的指令可能会被Hazard Unit控制冲刷掉)
- cycle2按照redirection_pc从I-Memory里取出指令放到FIFO头部
改进设计
核心思想是:尽可能保存预取指令,避免浪费
Ping Pong FIFO(PPF)思想
- 采用2个FIFO取指队列,当重定向产生导致FIFO需要冲刷的时候,暂时不要冲刷FIFO; 将指令暂时写入到另一个空闲的FIFO当中
- 重定向返回的时候,从之前的FIFO的去指令,利用预取的指令
TODO: 数学公式说明优化的收益
硬件实现
硬件上为了支持PPF需要实现的功能有:
额外的FIFO(5*16bits寄存器)
指令PC计算逻辑 & 旧指令选择逻辑
- 重定向发生的时候,提前根据重定向类型,将重定向返回时的指令对应的pc存储起来, 那么在重定向返回的时候,可以通过该寄存器的值快速得到指令对应的pc
- 旧指令选择逻辑需要根据重定向
ping pong FIFO控制逻辑
- 使用free[1:0]寄存器来表示ping pong FIFO里的内容是否有效
- 重定向发生的时候: 如果一个FIFO里的内容是无效的,则可以在重定向发生的时候,将新的指令写入到该FIFO里
- 重定向发生的时候,假如另一个FIFO空闲,其free寄存器对应字段拉低
- 重定向返回的时候,将当前FIFO对应的free寄存器位拉高
硬件实现

- 2个5*16的FIFO
- pc_instr寄存器用于记录FIFO头部的指令对应的pc
- free寄存器用于记录FIFO是否空闲,假如FIFO内部没有有效数据,则FIFO空闲
- waiting_for寄存器记录FIFO内指令对应内容,用于判断重定向的返回
举例说明

针对SBP导致的重定向,其waing_for寄存器应该是EXE Stage的PTNT信号
- 若下一个cycle没有得到该信号,则表示重定向正确,当前FIFO里的指令确实是无效指令,则free当前FIFO
针对中断&异常,会进入到中断服务程序去处理
如果ISR指令很多,则mret指令迟迟不能遇到->waiting_for信号迟迟不能拉高
此时一个FIFO相当于一直都是not free的,此时PPF退化成单一FIFO
设置一个Timer计数器,当Timer达到一定值的时候,丢弃FIFO里的内容
有利于分支指令、不利于ISR的返回

访存Leftover Buffer & Prefetch Buffer
问题描述
在访存的时候,若果存在lw+add这种的指令序列,由于没有MEM Stage->EXE Stage的bypass,则add指令需要等个1个cycle,造成1个bubble; 能否通过寄存器缓存D-Memory的内容,从而避免这个cycle的时间浪费?
Leftover Buffer
思想
- 将上次从D-Memory中取出的指令保存在寄存器里
- 下次访问同样地址时,可以直接从该寄存器里读数
硬件实现
- 硬件需要支持的功能:
- 保存上次访存的内容
- 访存是判断需要访问的地址对应的数据是否在Leftover buffer里
- 在D-Memory跟Leftover Buffer里选择数据
- 硬件实现:

- 优点:
- 在特定情况下能解决lw stall问题
- 并且可以避免D-Memory访问,节约功耗
- 缺陷:
- D-Memory访问很随机、因此不太可能访问到上次访问的数据
- 增加了组合逻辑,增加了MEM Stage的周期
Prefetch Buffer
思想
- 每次取数据的时候,取64bits的数据,放入到一个Prefetch Buffer中
- 在顺序访问D-Memory的时候,每个cycle都可以直接从Prefetch Buffer里取,并且更新Prefetch Buffer
硬件实现
硬件需要支持的功能:
- 每次取64bits数据
- 存放预取的32bits数据,更新Prefetch Buffer
- 在D-Memory跟Prefetch Buffer里选择数据
硬件实现:

优点:在顺序访问D-Memory的内存下(例如数组遍历)时,Prefetch Buffer能够连续地发挥作用,解决lw stall
访存设计
互联设计
通过MMIO,利用Load Store指令对加速器进行访问
- 访问加速器的延迟跟访问D-Memory的延迟不同(支持outstanding操作,避免等待ACC写入导致的pipeline stall)<- 参考AXI写操作
- 拓扑结构采用一主多从的结构,因为只有1个MCU Core
- Read的时候数据来源可能有D-Memory, Cache, ACC
低功耗设计
- Read的时候数据来源可能有D-Memory, Cache, ACC,根据地址空间对地址译码,产生片选信号,避免Memory的访问
实施性
Write to ACC register fast,从而保证写入的实时性。
综合结果


