RISC-V总线
RISCV 总线设计
主流总线:AHB, APB, AXI
AHB(Advanced High Performance Bus)
工作方式
重要部件:主设备(master), 从设备(slave), 译码器(decoder), 终裁器(arbiter), 复用器(mux)
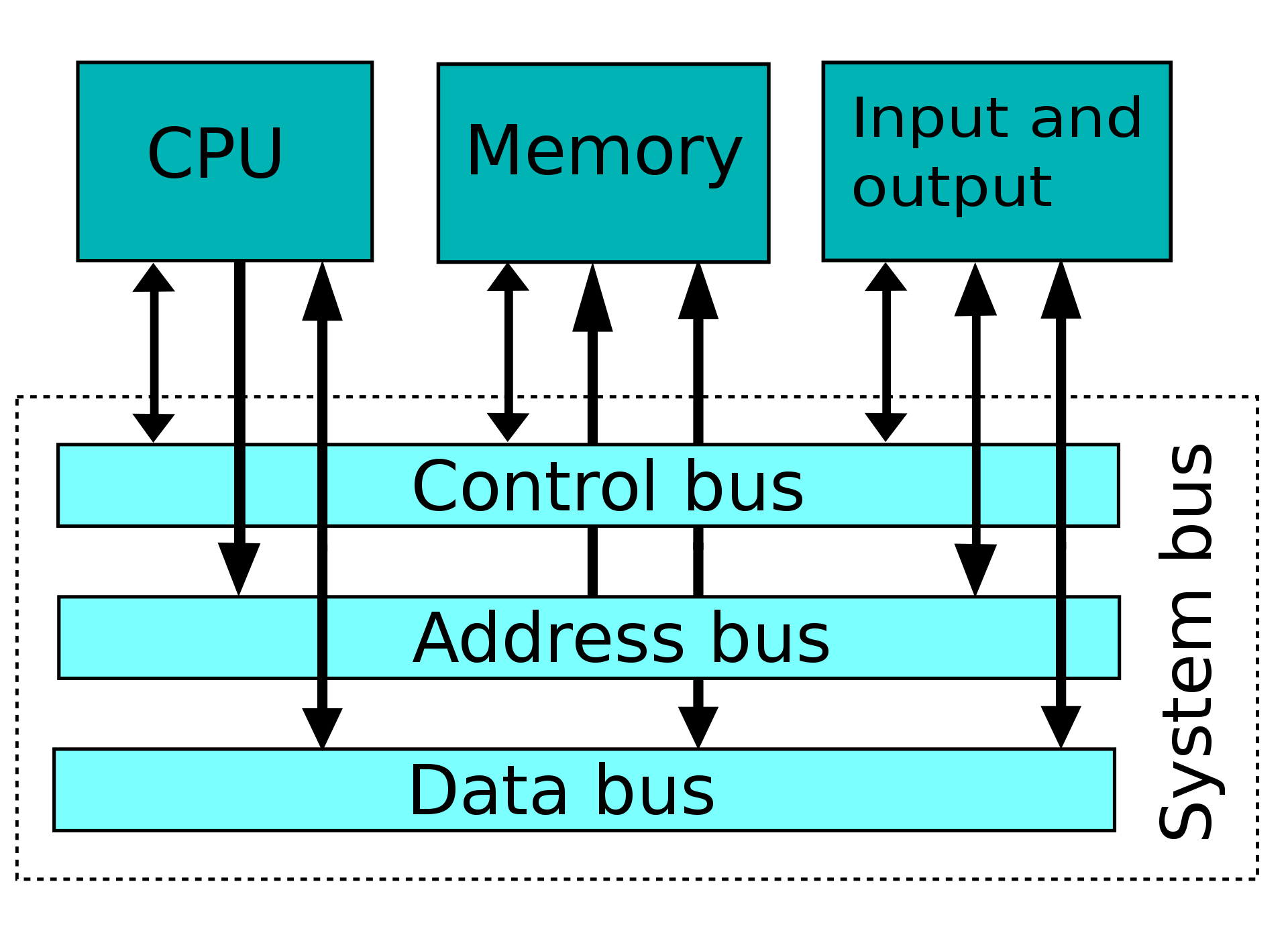
数据线: 地址线、数据线、控制线
工作过程
- 主设备需要占用总线的时候,需要想终裁器发送请求(request)
- 终裁器工具其优先级算法,选择一个主设备授权访问总线,其余的主设备此时不可以访问总线
译码器根据主设备提供的地址,生成从设备的片选信号来选择主设备想要访问的从设备 - 主设备发送地址和控制信号给从设备,从设备最快再下一个周期后返回传输成功的
HREADY信号 - 从设备如 Busy 则会将 ready 信号拉低,表示信号传输没有完成
- 若主设备收不到从设备对上一次控制信号的 ready 信号,则主设备需要将当前的地址和控制信号延迟到下一拍

优点
- 高性能低功耗:是目前最为广泛的高性能低功耗总线,例如 ARM Cortex-M 就大多采用 AHB 总线(M3, M4, M55)
缺点
- AHB 内部采用shared-bus的架构,基于复用器(mux-based)实现. 缺点在于:当主从设备变多事,AHB 的架构同一时刻只有一对主从设备可以通信,效率太低
- 没有采用 valid-ready 方式的握手信号
- 无法支持多个滞外传输(Multiple outstanding transaction)
The AHB is the backbone of the system and is designed specifically for high performance, high-frequency components. This includes the connections of processors, on-chip memories, and memory interfaces among others.
APB(Advanced Peripheral Performance Bus)
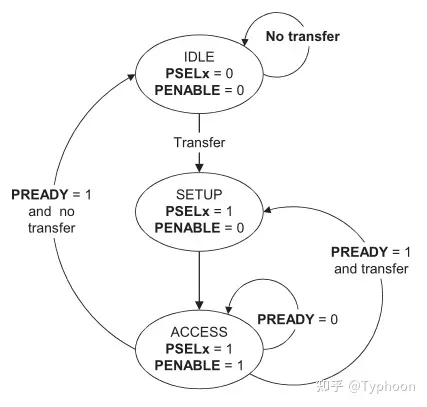
传输控制3个重要信号:
- sel
- enable: sel信号一定会拉高
- ready

- 优点
- 控制简单: 传输都有时钟上升沿同步,控制线数量少
- 硬件实现简单(只有一个 master:APB bridge,作为高速总线和低速设备之间的接口)
- 连接一些低速设备,如 UART, low-frequency GPIO, and timers
- 缺点
- 性能不好,带宽低

The APB is a simplified interface designed for low bandwidth peripherals that do not require the high performance of the AHB or the ASB.
AXI(Advanced eXtensible Interface)
工作方式
在 AHB 的基础上的改进
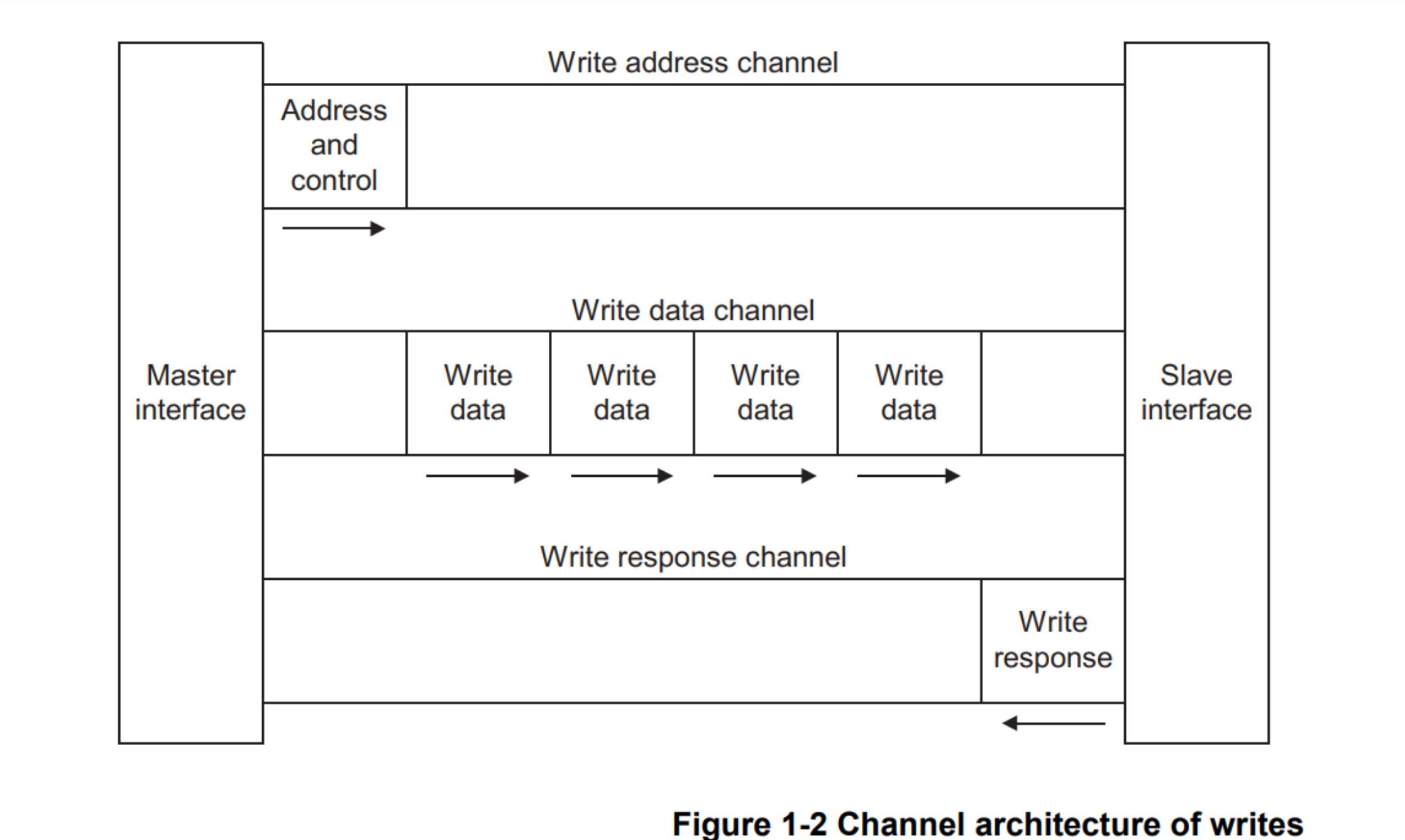
五个通道来处理器数据的发送和接收: Read address channel, Read data channel, Write address channel , Write data channel, Write response channel

支持乱序数据传输: 5 个通道都是对应的 ID 信号,传输的时候会给 Transaction 带上 ID,同一个 ID 的 Transaction 必须保证彼此之间的顺序;不同 ID 的 Transaction 不用保证顺序。因此可以让:快速的 Transaction 快速的完成,不用等待慢的 Transaction 完成了再完成快的。适合高性能、低时延的设计。
AXI 中必须顺序完成的传输,需要满足以下关系:- 来自同一个 master, 有同样的 M_ID
- 有着同样读写类型, 有同样的 r/w_ID
- 有着同样传输 ID 的传输,有同样的 AXI4_ID


通过 valid-ready 实现握手,valid 和 ready 信号彼此之间没有依赖性,可以自行拉高,从而避免了死锁。下图中橙色的是 master 的输出信号、蓝色的是 slave 的输出信号
single-request burst: 传输只需要给出首地址
突发传输(burst transactions)允许对具有特定地址关系的多个传输进行分组
- AXLEN[3:0]: 一次 burst 传输中,数据传输的次数(一次数据传输称为一个 beat)
- AXSIZE[2:0]: 一个 beat 的位宽,位宽不能超过总线的位宽
- AXBURST[1:0]: burst 传输的类型,固定模式、增量模式、循环模式

支持非对齐的地址: 非对齐的 burst 传输,只有第一个 beat 是非对齐的,后续的都是对齐的,下图展示了当传输宽度为 16bits、且开始地址从 0x03 开始的传输

优点
- 性能好: 目前应用最广泛的高性能总线
- 控制更加灵活: AXI
只定义了主设备和从设备之间的接口(interface), 本质上不是
Bus,而没有定义二者如何连接(AHB
实际是定义了总线内部架构的),而是由实现者自己定义。
例如:如果读写通道使用独立的译码器和终裁器,则可以实现:mater1 --write--> slave1, master2 --read--> slave1同时发生
缺点
- 复杂:控制复杂(控制信号多,在 SoC 中集成不当容易死锁)、硬件实现复杂
- 功耗:在低功耗 SoC 中,AXI 功耗显得过高
总线设计
总线的设计主要包括两个重要的部分:
接口设计(interface): 接口设计主要定义相关信号线的功能、时序等信息,以及总线数据传输的特点,例如
命令通道
信号名 方向 宽度 介绍 sReady input 1 从设备就绪 mValid output 1 主设备信号有效 read output 1 写或读 addr output DW 地址 wData output DW 写数据 wMask output DW/8 写 Mask 反馈通道
信号名 方向 宽度 介绍 mReady output 1 主设备就绪 sValid input 1 从设备信号有效 rError input 1 从设备读数据错误 rData input DW 从设备读数据
内部总线架构设计(bus internal architecture):
- 总线的内部组件:终裁器、译码器、复用器等
- 主设备和从设备的连接方式:一对多、多对多等

H Bus 设计评价
- 采用 shared-bus 的结构:
- Master 在下发任务的时候,采用 FIFO 机制,FIFO 最前面的 master
授权总线,缺点如下:
- shared-bus 结构,master 需要竞争总线,导致实时性降低
- 采用 FIFO 结构,无法控制 master 的优先级
- 如果 FIFO 头部的 master 占用总线的时间最长,则整体总线等待的时间也会最长
- Slave 在返回数据的时候,采用轮询机制,缺点如下:
- shared-bus 结构,slave 需要竞争总线,导致实时性降低
- 由DSP 软件控制轮询加速器的状态:根据软件地址 ,查询对应加速器的状态寄存器; 软件查询状态、控制加速器的效率都很低(软件控制需要设计到函数调用、保存上下文、函数返回、甚至是处理器优先级的切换)
- Master 在下发任务的时候,采用 FIFO 机制,FIFO 最前面的 master
授权总线,缺点如下:
🌟 如果可以设计好 MCU 和 co-processor 的交互接口、采用硬件的方式实现 co-processor 的“状态查询”和“控制”,则效率相比于软件会高很多;将 shared-bus 结构的总线改为 point-to-point 结构的 bus,则总线架构也会优化很多。 配置信息的下发从文档中看主要靠 DMA 和 load/store,如果可以优化 laod/store 指令,则 mcu 调度 co-processor 能力应该会增加
附录
- AXI 读通道信号

- AXI 写通道信号

- AHB 通道信号

- APB 通道信号

参考文献
总线学习记录
AXI总线
信号说明
写地址信号
| 信号名 | 信号源 | 信号说明 |
|---|---|---|
| awawid[3:0] | master | |
| awaddr[31:0] | master | |
| awlen[3:0] | master | burst传输的次数 |
| awsize[2:0] | master | 每次传输的位宽 |
| awburst[1:0] | master | burst传输的类型 |
| awlock[1:0] | master | |
| awcache[3:0] | master | |
| awport[2:0] | master | protection |
| awvalid | master | |
| awready | slave |
写数据通道
| 信号名 | 信号源 | 信号说明 |
|---|---|---|
| wid[3:0] | master | |
| wdata[31:0] | master | |
| wstrb[3:0] | master | byte write enable |
| wlast | master | |
| wvalid | master | |
| wready | slave |
ID用于支持乱序传输,在AXI4协议中发现写乱序提升性能效果不大, 因此去除了WID,即去除了写乱序的操作,但保留了读乱序操作
写反馈通道
| 信号名 | 信号源 | 信号说明 |
|---|---|---|
| bid[3:0] | slave | |
| bresp[1:0] | slave | 写入的状态 |
| bvalid | slave | |
| bready | master |
读地址通道
| 信号名 | 信号源 | 信号说明 |
|---|---|---|
| arid[3:0] | master | |
| araddr[31:0] | master | |
| arlen[3:0] | master | |
| arsize[2:0] | master | |
| arburst[1:0] | master | |
| arlock[1:0] | master | |
| arcache[3:0] | master | |
| arprot[2:0] | master | |
| arvalid | master | |
| arready | slave |
读数据通道
| 信号名 | 信号源 | 信号说明 |
|---|---|---|
| rid[3:0] | slave | |
| rdata[31:0] | slave | |
| rresp[1:0] | slave | 读数据操作的状态 |
| rlast | slave | |
| rvalid | slave | |
| rready | master |
AXI读写时序
- AXI突发读传输
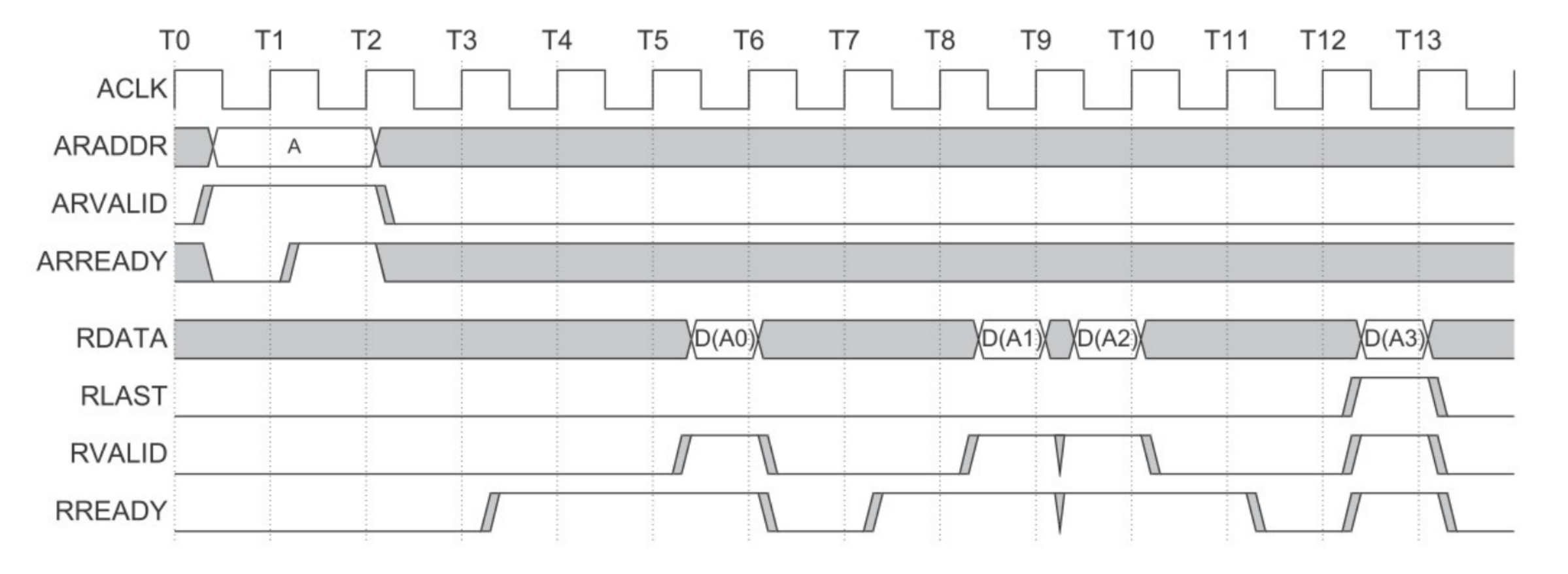
- Overlapping突发读传输
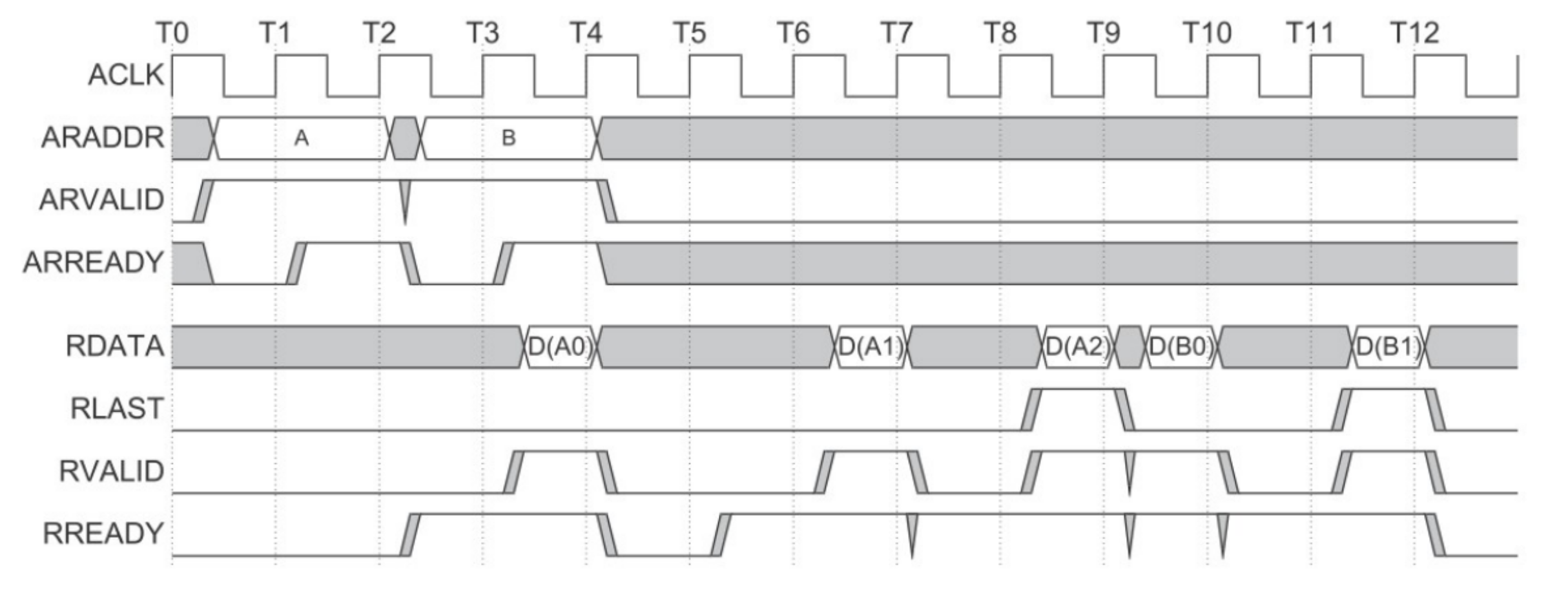 slave在第一次突发读传输完成后处理第二次突发读传输。
也就意味着,主机一开始传送了两个地址给设备。设备在完全处理完第一个地址的数据之后,才开始处理第二个地址的数据
slave在第一次突发读传输完成后处理第二次突发读传输。
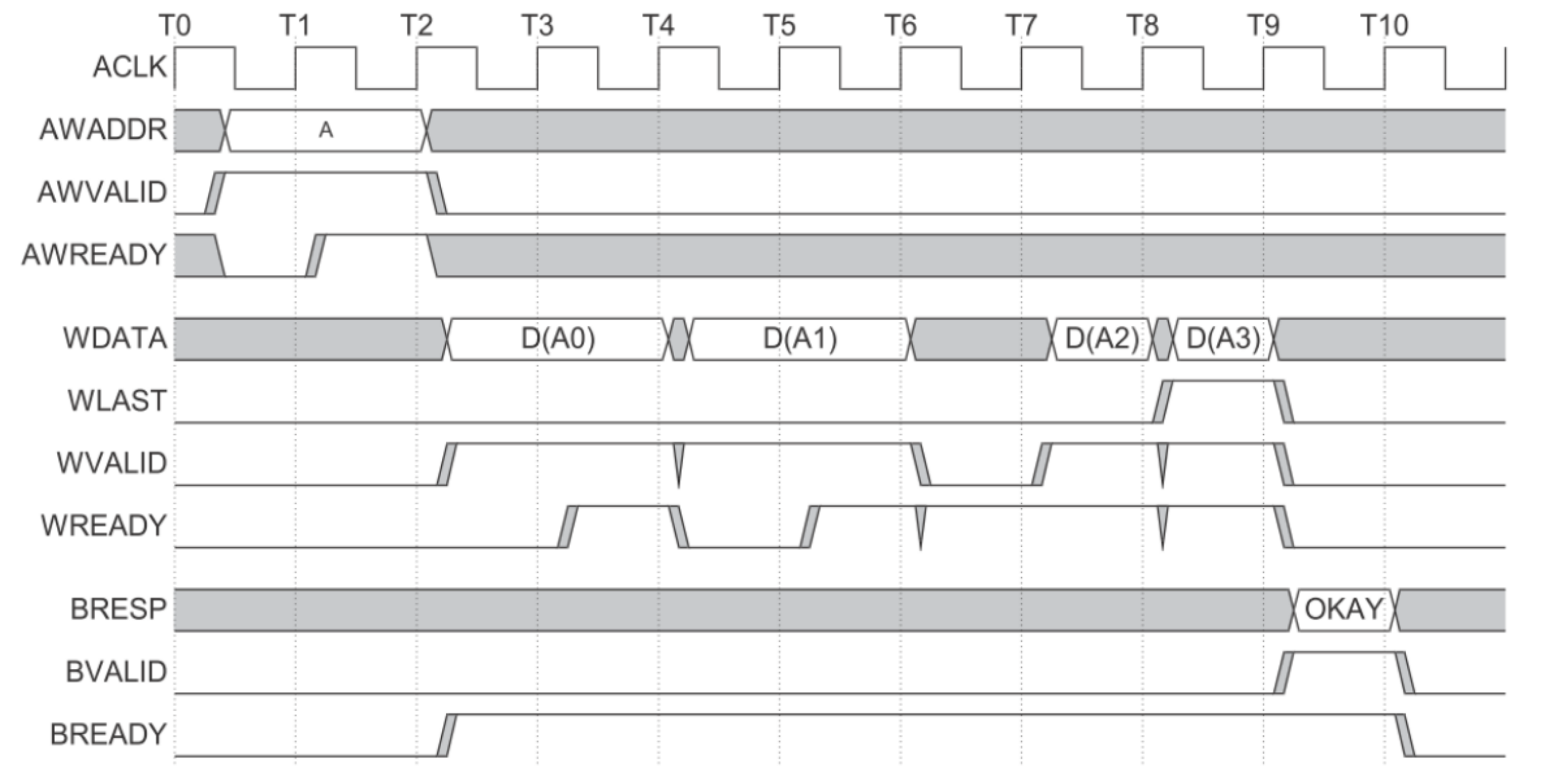
也就意味着,主机一开始传送了两个地址给设备。设备在完全处理完第一个地址的数据之后,才开始处理第二个地址的数据 - AXI突发写传输
AXI Outstanding传输
outstanding是指主机在没有收到response时可以发起多个读写transaction的能力。
- 简单讲,如果没有outstanding,则总线Master的行为如下(AHB就不支持outstanding): 1)读操作:读地址命令 -> 等待读数据返回 -> 读地址命令 -> 等待读数据返回 -> .. 2)写操作:写地址命令->写数据->等待写响应返回->写地址命令->写数据->等待写响应返回..
- 如果支持outstanding,那么总线就可以在没等到response时,连续发多个读或写的命令,然后再逐个等待命令的返回: 1)读操作:读地址命令 -> 读地址命令 -> 读地址命令 -> 等待读数据返回 ->等待读数据返回 ->等待读数据返回.. 2)写操作:写地址命令->写地址命令->写地址命令->写数据->写数据->等待写响应返回->写数据->等待写响应返回->等待写响应返回..
AXI乱序传输
- 由于AXI 支持Outstanding传输,因此master在收到response之前,可以发送多次传输请求
- 同一个id的传输,必须按顺序;不同的id的传输,可以乱序
