RISC-V 乱序执行
乱序执行微架构学习笔记:
记分牌 Score Board
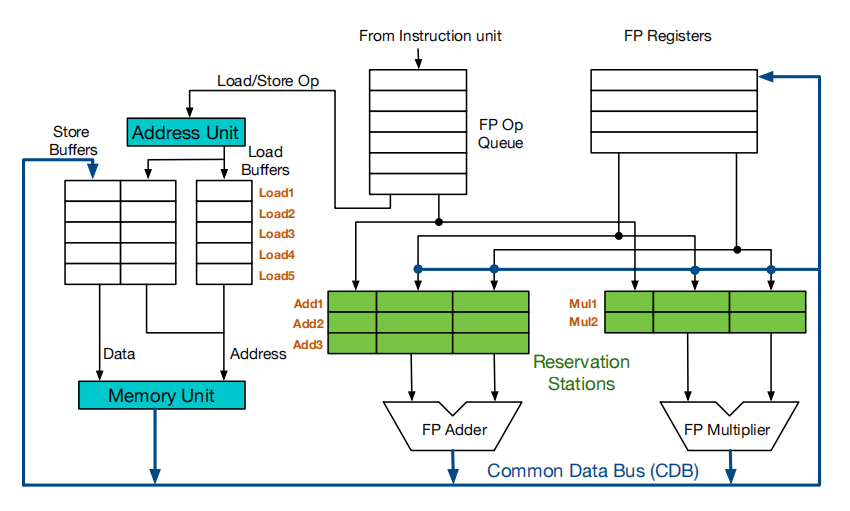
特点:顺序发射、乱序执行、乱序完成
优点:简单&能够实现乱序执行
缺点:
- WAR(写回时判断), WAW(发射时判断) 都会导致 stall
- 顺序发射:即使两条指令需要的是不同的功能部件,后者也会因为前者的阻塞而阻塞
- 不是按序完成,对于 debug 比较困难
Tomasolo
通过寄存器重命名(Register Renaming)可以消除假数据依赖 WAW,WAR
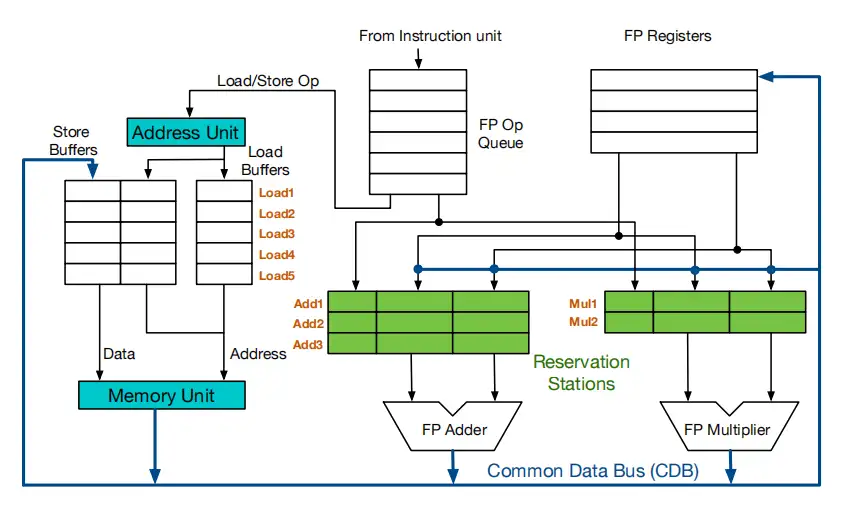
在记分牌上面的改进:
- 每个数据通路配有保留站,可以缓存多个属于该数据通路的指令, 只要保留站有空余位置,相关数据通路的指令就可以被发射到保留站中,然后在保留站中等待源操作数
- 保留站回直接把需要的数据缓存下来,不用再从寄存器里去读数: 保留站中每一条指令都会在数据更新的时候第一时间将源操作数存到保留站中,避免了 WAR
- 指令在发射的时候会更新寄存器表:指明该寄存器的值由更新的指令计算得到,避免了 WAW
- 指令计算完成之后就可以进入到写回阶段,写回的数据通过 CDB 通知 RF 和所有的保留站,保留站中的相关源数据依赖会被替换成 CDB 广播的数据、RF 中依赖该计算单元的数据也会被 CDB 的数据更新
- 保留站中的指令在没有等到源操作数的时候不会被发射,而是标记其源操作数由何计算单元得到,避免了 RAW
PS: 保留站中直接缓存了源操作数的依赖关系,并且会根据 CDB 的广播直接更新,其本质是”提供了额外的寄存器,实现了寄存器重命名“
- 优点:避免了记分牌算法中应为 WAW, WAR 导致的 stall
- 缺点:
- 当保留站中多条指令同时就绪的时候,需要一种逻辑来选择一条指令放到运算单元中运算
- 当多个运算单元同时完成计算的时候,需要竞争 CDB 来进行广播
- 在超标量处理器中,一次译码多条指令、并且一次发射多条指令到保留站中(如何保证这些指令发射到保留站中的顺序?)
- Load, Store 如果有相同的地址时,如何保证数据正确?
- 乱序提交、不支持精确异常
Reorder Buffer
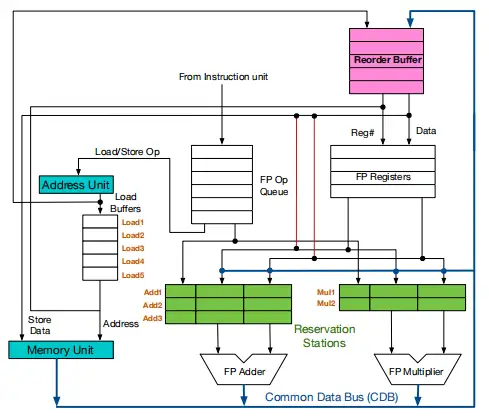
- 指令发射的时候会被同时发射到 ROB 和 RS,并且 RS 和 RF 都会指向 ROB,表明其依赖 ROB 中的结果更新
- 计算完成的时候,广播通知 ROB 和 RS
- commit 的时候只会更新 ROB 中最老的那条指令,指令只有 commit 的时候,才可以将数据写入到 RF,实现按序提交
- ROB 中待提交的数据是有效数据,因此可以被 RS 读取用于源操作数
在 Tomasolo 的基础上,利用 ROB(类似 FIFO)记录程序的指令的执行顺序 -> 实现指令的按序退休,从而实现精确异常
- 优点:
- 使用 ROB 来索引 RS 和 RF,当 RS 中的指令进入 exe 的时候,就可以从 RS 中清除该指令
- 方便流水线冲刷:直接将 ROB 中后续的所有指令冲刷即可
- 缺点
- 增加了硬件存储:源操作数可能在 RF, ROB, RS
- 指令读取数据不仅通过逻辑寄存器和 CDB,还通过 ROB,这需要 ROB 配置读口,增大布线压力,且要在读取数据的线路的末尾增加选择器(把 ROB 的数据加入到选择器中),这会潜在地增加关键路径长度。在多发射的处理器中,ROB 需要支持多端口读,在一个四发射的机器里,ROB 需要支持八个读端口,压力很大。
Register Renaming
ROB
ROB 编号会被映射到 RF,从而实现了虚拟寄存器到物理寄存器的映射,新的指令发射的时候尝试从 RF 中读源操作数,若发现该寄存器已经映射到了 ROB 中的表项,则新的指令更新其依赖关系为对应 ROB 编号
- 优点:逻辑简单
- 缺点:
- 所有指令都会进入 ROB,包括不会写 RF 的指令如 Store,相当于会浪费一个物理寄存器(ROB1 个表项就是一个物理寄存器)
- 硬件复杂、布线复杂、ROB 需要多个读端口
统一寄存器
🌟乱序处理器核架构学习
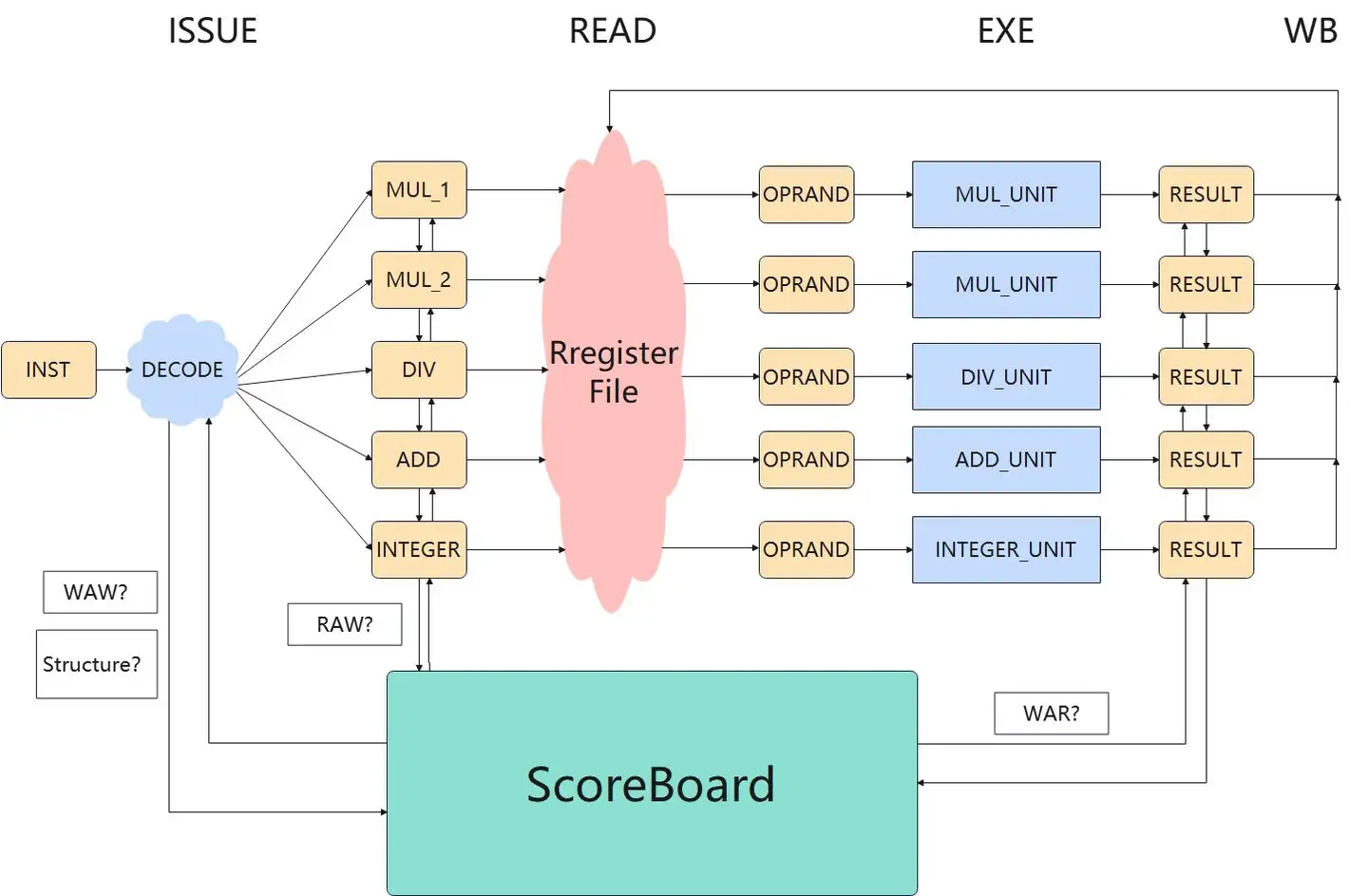
计分牌算法(Scoreboard)
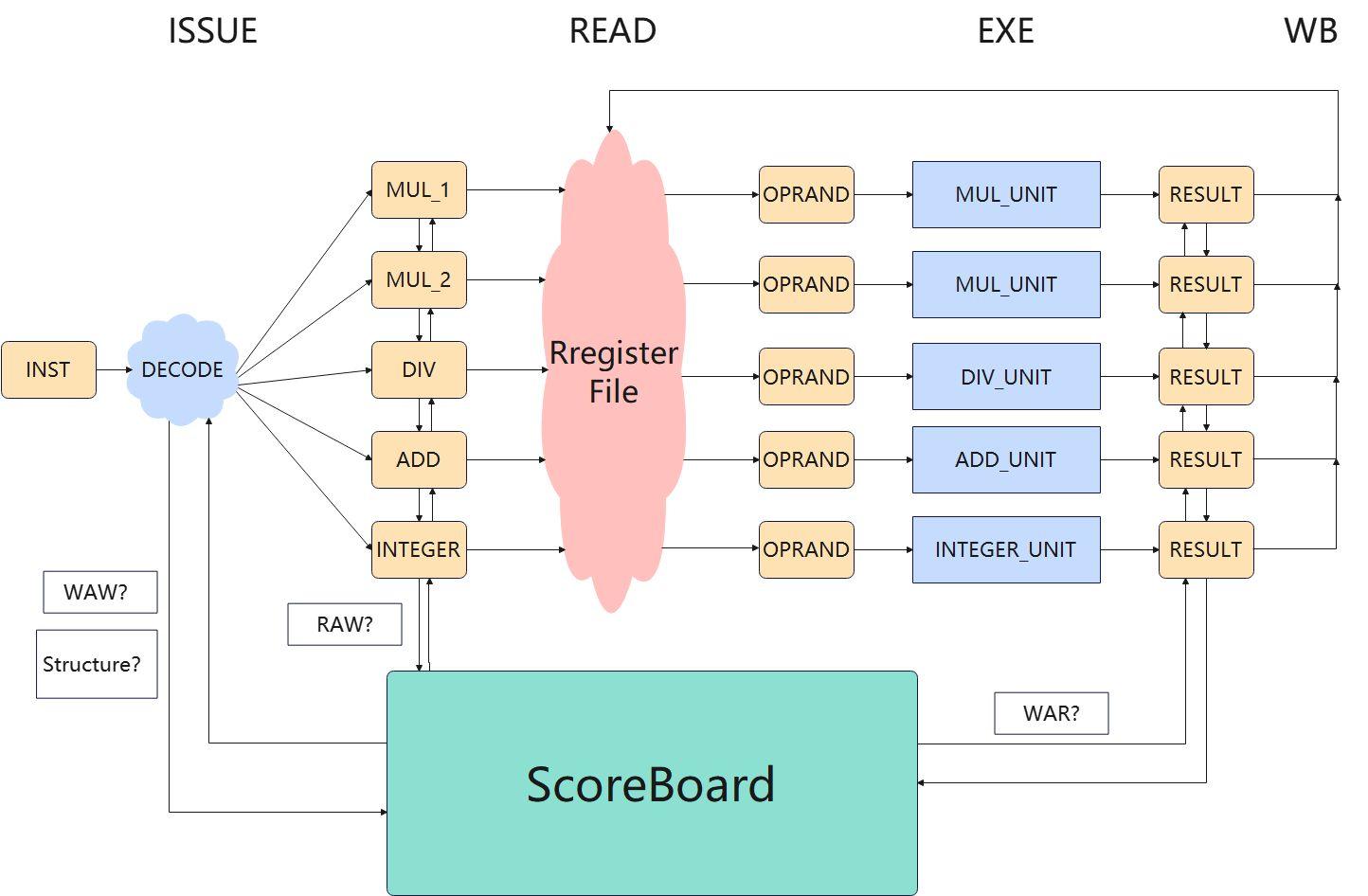
单发射乱序架构:
- 乱序体现在:不同数据通路之间的指令,彼此之间可以乱序执行
- 单发射体现在:只有一个
INST寄存器,每次只能DECODE一条指令
INST经过DECODE单元进入到部件寄存器(MUL_1, MUL_2, etc)时:
- 查询ScoreBoard,如果当前指令的目的寄存器被占用,则当前指令不会发射到部件寄存器中
- 目的是为了避免WRW;会导致流水线STALL
- 会导致DECODE阻塞,所有的指令都会stall,非常严重的性能降低
部件寄存器到操作数寄存器(OPRAND):
- 查看指令的两个源寄存器是否需要由其他部件计算得到
- 如果需要计算得到,则会停留在部件寄存器阶段、不会读取Register File进入到操作数寄存器阶段
- 避免RAW:如果源操作数正在别的功能单元里计算,那么此时从寄存器里读取到的操作数,自然是过时的
操作数寄存器到结果寄存器(RESULT):
- 操作数寄存器里的指令已经具备读取操作数的能力
- 当对应的计算单元空闲的时候,就可以进行计算了,计算完成之后结果会写入到RESULT寄存器里
- 提交的时候会查看ScoreBoard,是否有别的操作数准备就绪但是还没有开始计算的指令,看它们的源寄存器 跟当前指令的目的寄存器是否一致,如果一致则当前指令不能提交;会导致流水线STALL
- 避免WRA:别的指令想要读取旧的寄存器的值,所以我们必须等这些指令把寄存器的值读走了之后,再覆盖掉寄存器
- 提交的时候是乱序提交
ScoreBoard优缺点总结:
- 优点:实现简单
- 缺点:
- 单发射、一条指令阻塞可能会导致流水线阻塞
- 乱序提交
- WAR, WAW都会导致流水线STALL
Somasulo算法
借助寄存器重命名的思想,解决了假数据冒险(WAW, WAR)
- WAW:把最新的值写入到RF,旧指令的结果不写入RF,采取广播的方式通知其他指令
- WAR:不会出现该冒险,指令发射的时候,会把寄存器的值copy一份,这样就不会担心想要旧的值,但是寄存器被写入导致覆盖