RISC-V分支预测器设计
- 分支预测器的作用
- 主流的分支预测器
- 开源项目中使用的分支预测器
目录 [TOC]
分支预测
预测不跳转(always not taken)
- PC+=4
- 尽快检测分⽀结果 -> 减少错误预测惩罚
- 如果在 EXE 阶段已知分⽀结果,则必须刷新 2 条后续指令
- 如果在 ID 阶段已知分⽀结果,则必须刷新 1 条后续指令
在译码级判断分之结果
优点:减少误预测惩罚(misprediction penalty) -> 减少 CPI(clock per instruction)
缺点:
- 可能增加时钟周期\(T_c\)
- 译码阶段的额外硬件成本
- 判断分之结果:需要比较器、bypass to ID stage
- 计算目的 PC: 额外的加法器
分支预测器对流水线性能的影响
程序中各种类型的指令概率如下:
- 25% loads
- 10% stores
- 11% branches
- 2% jumps
- 52% R-type or I-type
假设:
- 40%的
lw指令的结果会被下一条指令用到 - 25%的 branch 指令预测错误
- 所有的 JAL, JALR 会导致其下一条指令刷新-> \(CPI_{jump}=2\)
CPI 计算
理想的流水线处理器的 CPI= 1.
- Load/Branch CPI = 1 when no stall/flush, 2 when stall/flush. \[ CPI_{lw}=1*0.6+2*0.4 = 1.4\\ CPI_{branch}=1*0.75+2*0.25=1.25 \]
- 平均 CPI 是所有类型指令 CPI 的加权平均 \[ CPI_{average}=0.25*1.4+0.1*1+0.11*1.25+0.02*2+0.52*1 = 1.15 \]
流水线周期\(T_c\)
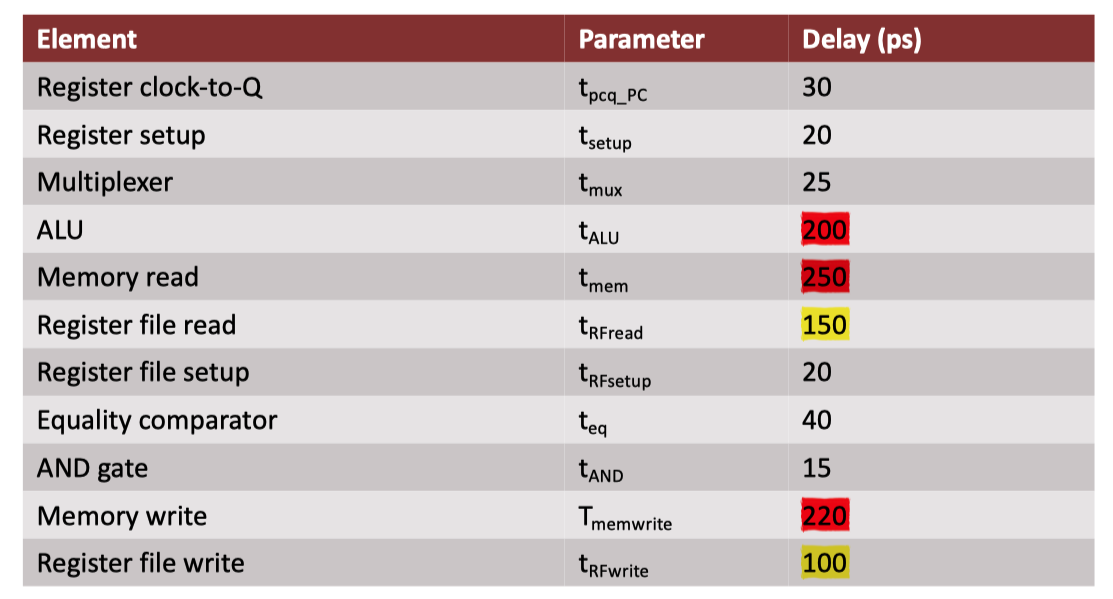
\[ \begin{align*} T_c = max\{&T_{IF}, T_{ID}, T_{EXE}, T_{MEM}, T_{WB}\}\\ =max\{\\ &t_{pcq}+t_{mem}+t{setup}\\ &\mathbf{\underline{2(t_{RFread}+t_{mux}+t_{eq}+t_{AND}+t_{mux}+t_{setup})}}\\ &t_{pcq}+t_{mux}+t_{mux}+t_{ALU}+t_{setup}\\ &t_{pcq}+t_{mem}+t_{setup}\\ &2(t_{pcq}+t_{mux}+t_{RFwrite}+t_{setup})\}\\ \mathbf{T_c}=\mathbf{T_{ID}}&=550ps \end{align*} \]
重要提示:ID 不应该是关键路径,通常IF 或MEM 可能是关键路径。可以轻松地将 ID 分解为多个 cycle,但很难将 MEM 分解为多个 cycle。
在此设计中,我们犯了 2 个错误,导致 ID 成为关键路径:
1.我们在 ID 中做分支决策
- Nutshell 在 EXE 中做分支决策,它的 BRU 可以是一个单独的单元,也可以复用 ALU 来计算分支决策和目标 PC。
- Nutshell 将分支决策从 EXE 传递给 WB(WB 还从 CSR 和 MOU 收集其他重定向信息),然后 WB 将目标 PC 发送到 IF
- RF 在前半个周期写入、后半个周期读出 -> ID 只有一半的时钟周期来完成它的工作,所以它的 CPI 需要乘 2
- Toast-RV32i 在 clk 的 posedge 上写入 RF,使用组合逻辑读取 RF,当 i_addr == o_addr 通过一个 2 选 1 选择器直接选择 write_data 作为 read_data
在何时做分之判断,ID or EXE?
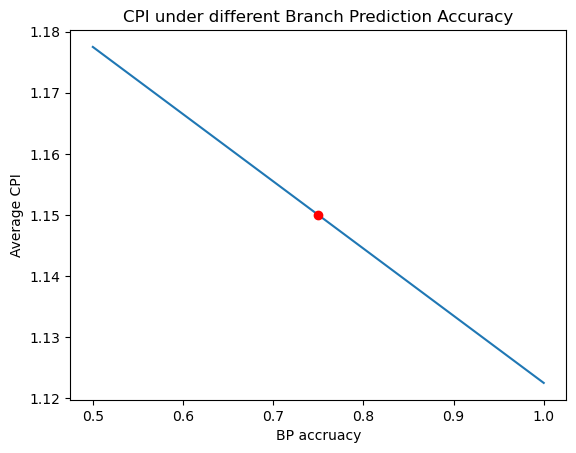
如果不在 ID 做分支判读,而是在 EXE 做分支判断,则得到的平均 CPI 如下:
\[ \begin{align*} CPI_{branch}&=1*0.75+3*0.25=1.5\\ CPI_{average}&=0.25*1.4+0.1*1+0.11*1.5+0.02*2+0.52*1 = 1.175 \end{align*} \]
是之前平均 CPI 的 1.175/1.5=1.02 倍,并没有显著增加\(CPI_{average}\).
但是在 EXE 做分支判断可以复用 ALU
的硬件并且缩短 critical path 从而降低\(T_c\)
但是在 EXE 做分支判断可以复用 ALU 的硬件并且critical path 从 ID 变成 EXE, 可能会降低\(T_c\),因此建议在 EXE 做分支判断。
\[ T_{program}=Amount_{instructions}*CPI_{average}*T_{c} \]
分支预测的流水线映射
动态分支预测
使用 BTB, RAS, PHT 在 IF 的时候做动态分支预测,在 EXE 经过计算判断分支指令实际的跳转方向和目的 PC,用于判断是否需要冲刷流水线&更新 IF 级的分支预测器
动态分支预测器的优缺点如下:
优点:
- 由于使用了BTB,可以直接在 BTB 中存储指令的类型,则 IF 不用通过 pre-decode 就可以判断当前指令的类型
- 由于使用了BTB,则可以直接根据预判的指令类型,配合 RAS 和 PHT 得到对应的跳转地址,避免了计算 target pc、也避免了delay slot 的引入
- 预测情况的判断很简单:只存在预测正确&预测错误两种情况 <- 所有的指令的类型、是否跳转、target pc 都在 IF 得到,所有指令实际的跳转结果、target pc 都在 EXE 阶段得到
缺点:
- 如果要保证预测的准确率,需要维护一个 BTB、RAS、PHT,在 IF 会带来额外的硬件、功耗开销
- BTB 是 content addressable memory,根据 PC 在其中遍历时间延迟较高,可能会导致 IF 成为 critical path
- 分支预测器需要根据 EXE 的结果进行更新,如果预测错误会需要冲刷后续 2 条流水线,则 miss penalty 是 2 个 cycle
动态分支预测器有如下两种可能预测的情况:
- 预测错误:
- 预测分支指令跳转、但是经过计算得到结果之后发现其不跳转
- 预测分支指令不跳转、但是经过计算得到结果之后发现其跳转
- 预测正确:
- 预测分支指令跳转、但是经过计算得到结果之后发现其跳转
- 预测分支指令不跳转、但是经过计算得到结果之后发现其不跳转
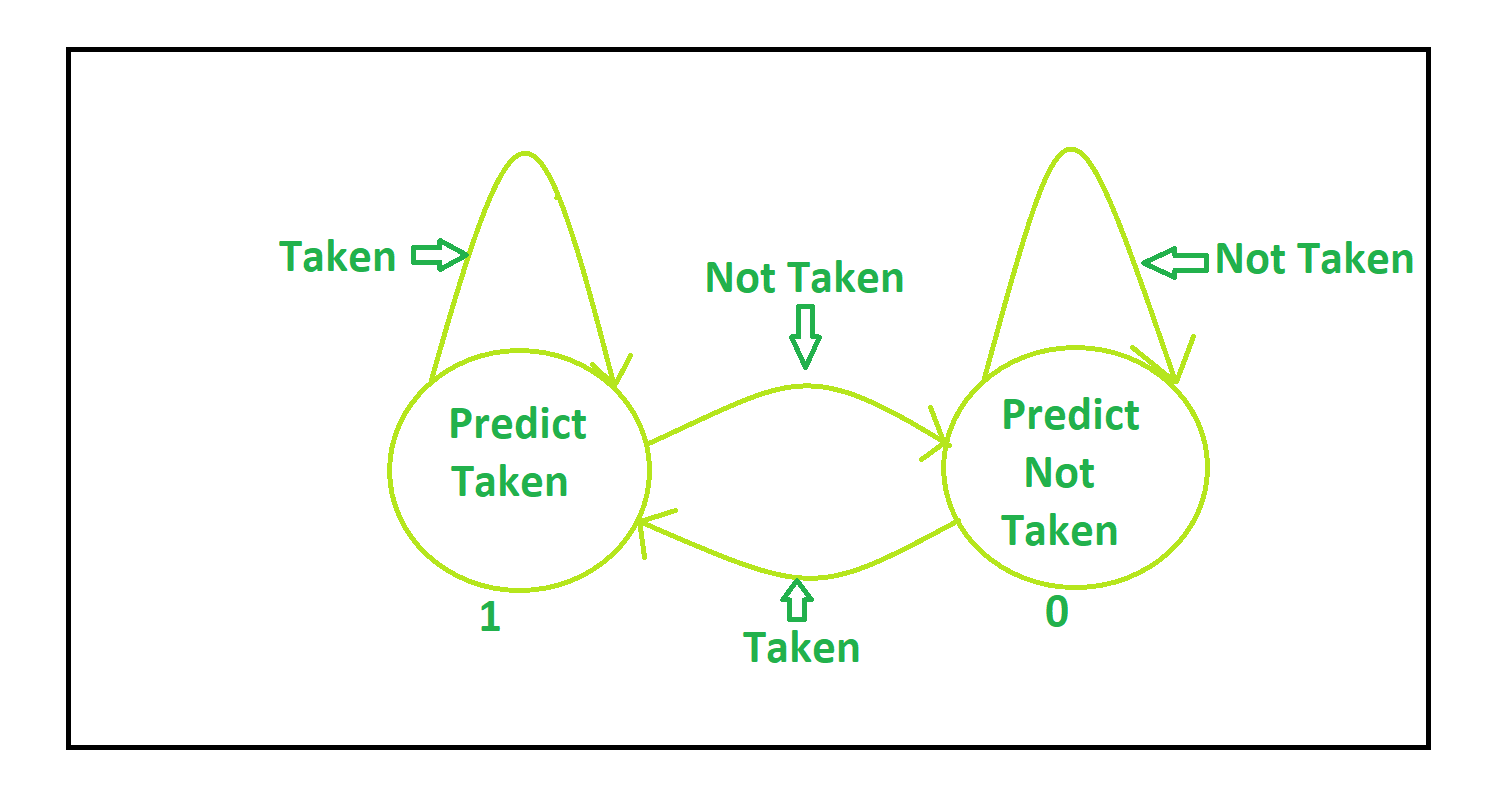
| 实际跳转 | 实际不跳转 | |
|---|---|---|
| 预测跳转(PC=Target PC) | ✅ | ❌ |
| 预测不跳转(PC+=4) | ❌ | ✅ |
- ✅:预测正确(Prediction Success)
- ❌:预测错误(Prediction Fail)
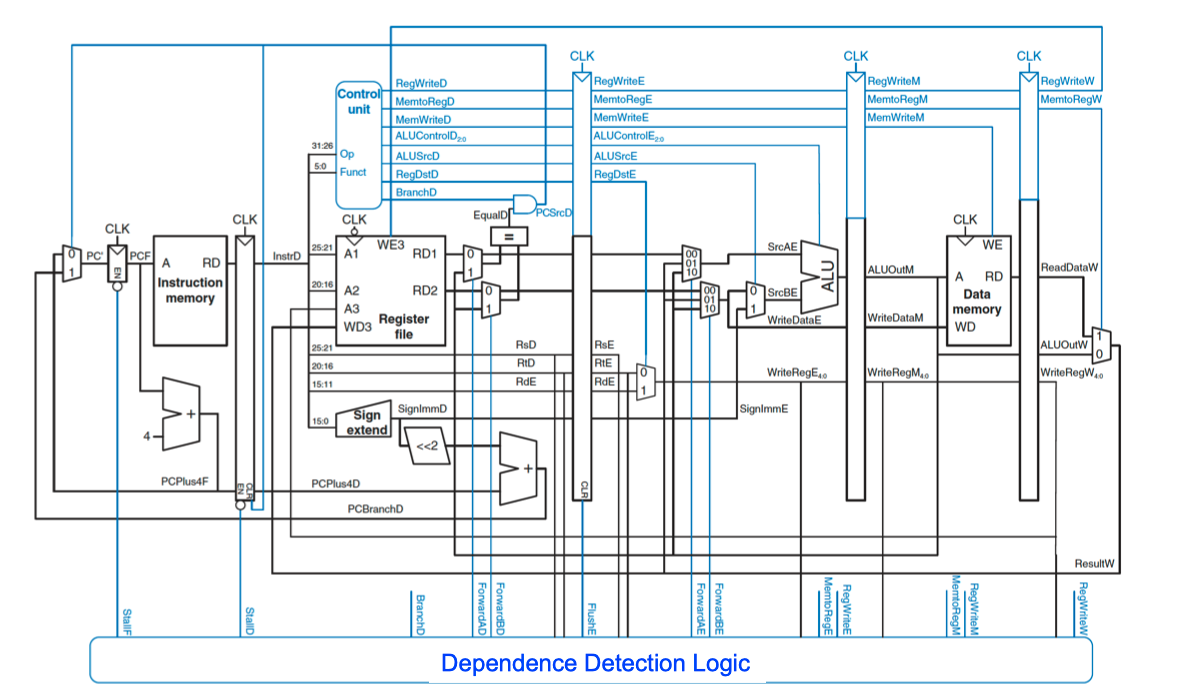
在 EXE 判断分支预测错误
- redirection PC
- flush ID Pipeline Register
- flush EXE Pipeline Register
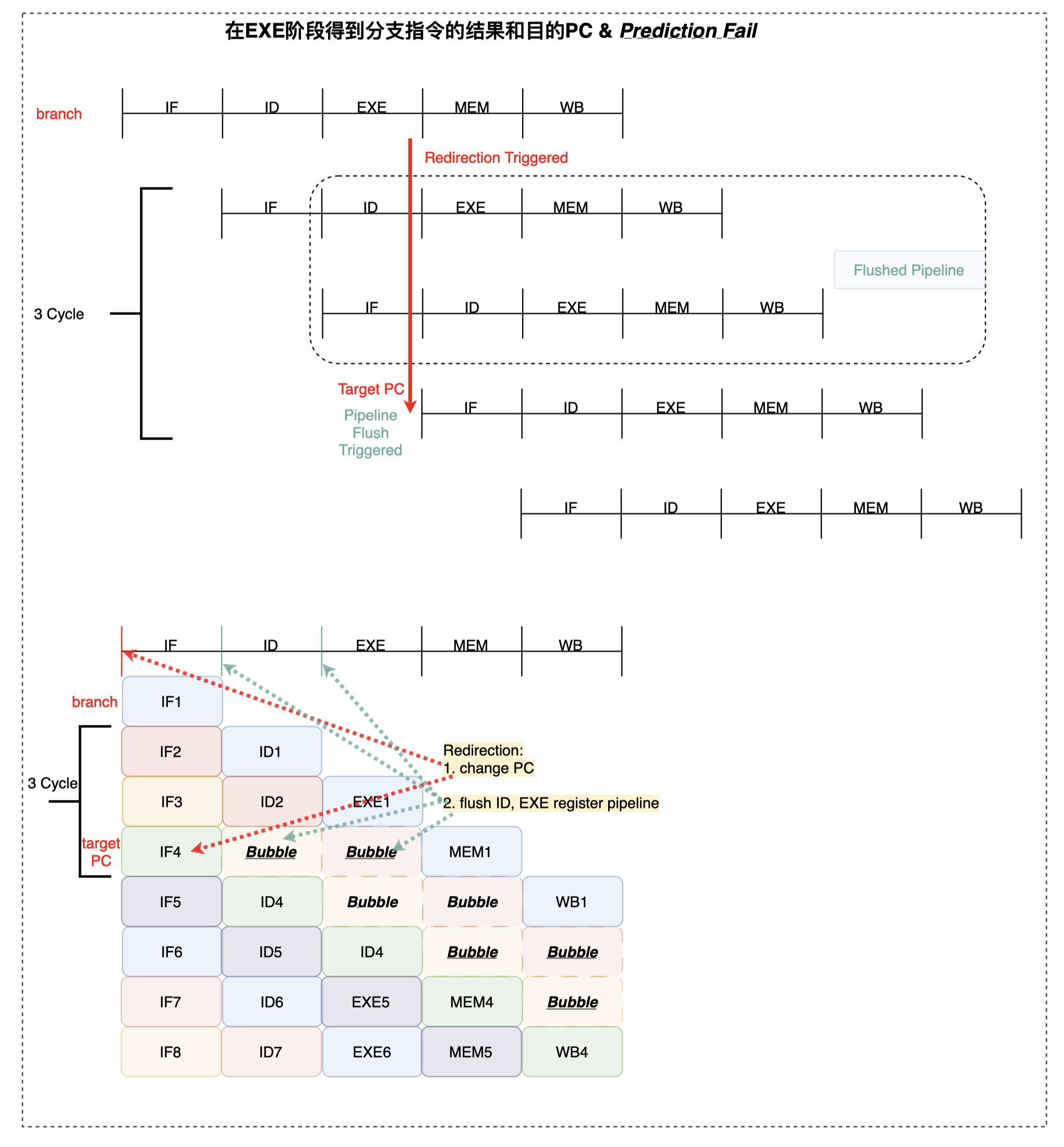
在 EXE 判断分支预测正确
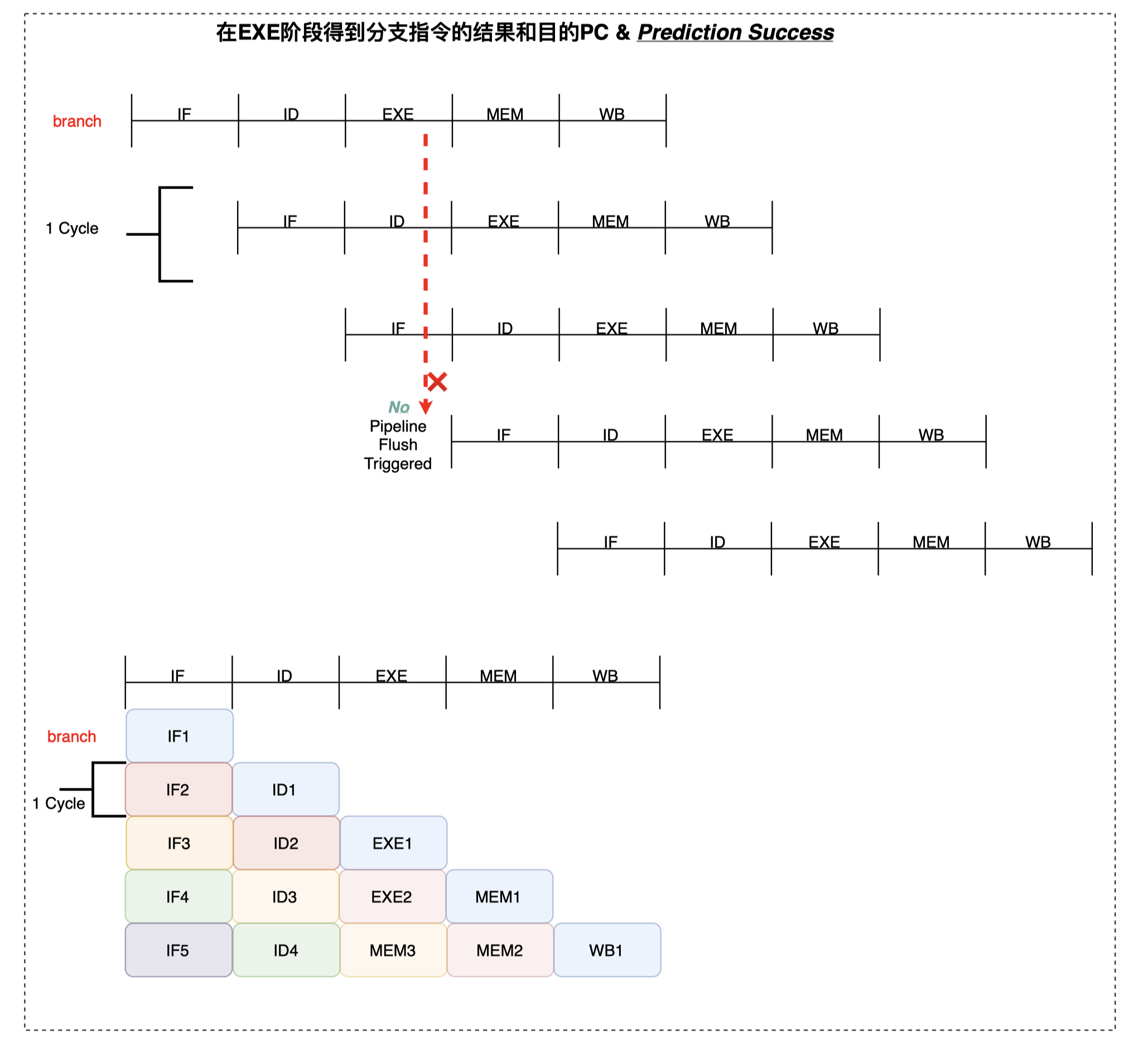
ID 阶段静态分支预测
静态分支预测器首先通过译码判断当前指令是否是分支指令,如果是分支指令则采用固定的分支跳转策略做分支处理;在 EXE 阶段计算得到真是的分支结果之后,判断分支预测器是否错误,如果错误再进行重定向处理
静态分支预测器的优缺点如下:
优点:硬件实现简单
- 可以复用 ID 阶段的译码器来判断指令的类型
- 如果实现了到 ID 的 bypass,则 bypass 的结果也可以复用
- 只需要在 ID 阶段添加计算 target pc 的加法器即可
缺点:
- 如果当前指令在 ID 阶段预测跳转,则其后面那条指令必须被冲刷掉 <- 因为 IF 阶段没有 BP 的功能,BP 的功能被后移到了 ID 阶段
静态分支预测器针对不同的分支指令其指令流水线是不同的
针对 JAL 和 JALR 指令:其必定会发生跳转; 在 ID 阶段会计算到下一条指令真实的 target pc、会冲刷到此时 IF 阶段的指令
JAL, JALR 的 miss penalty 恒为 1 个 cycle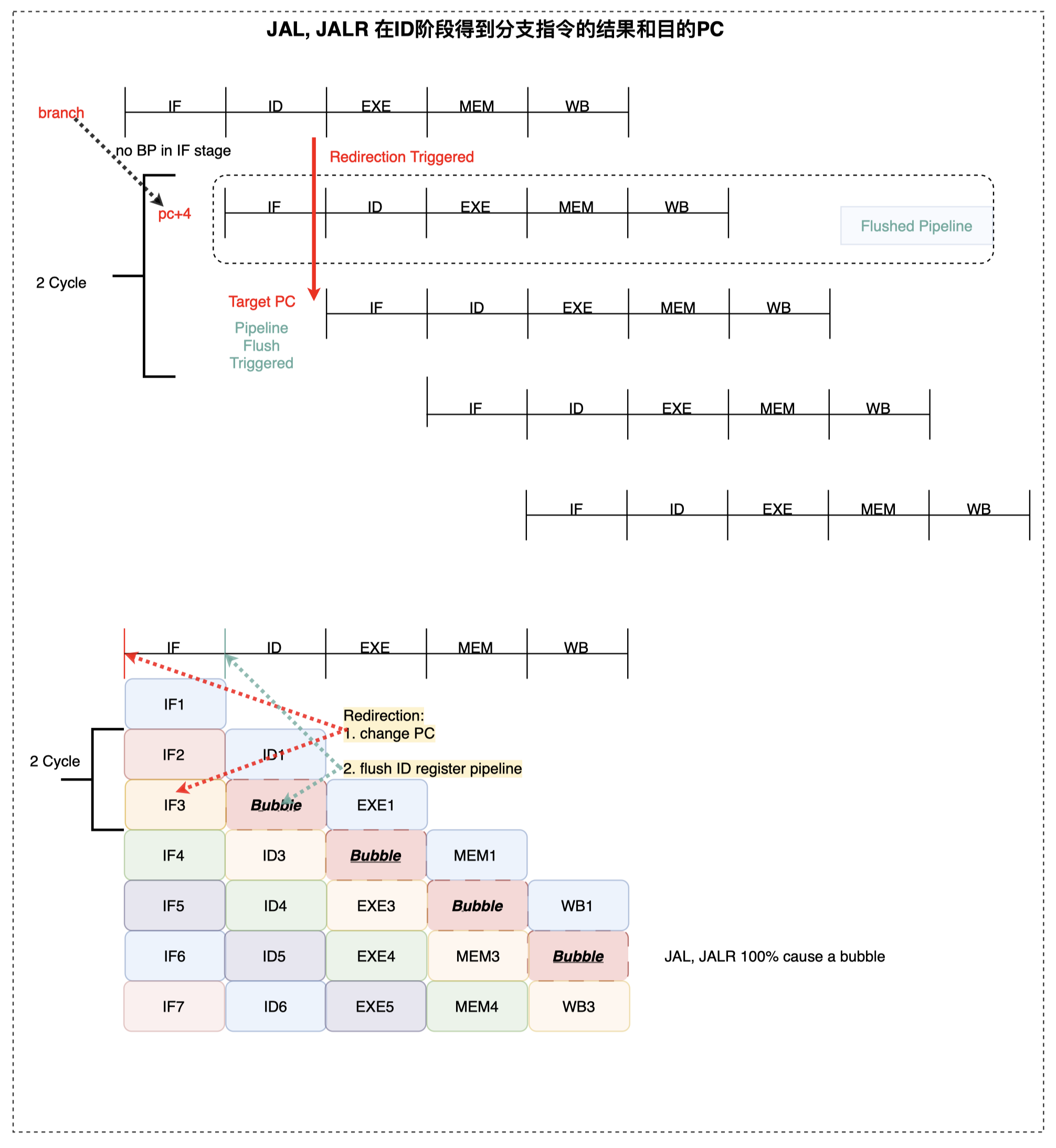
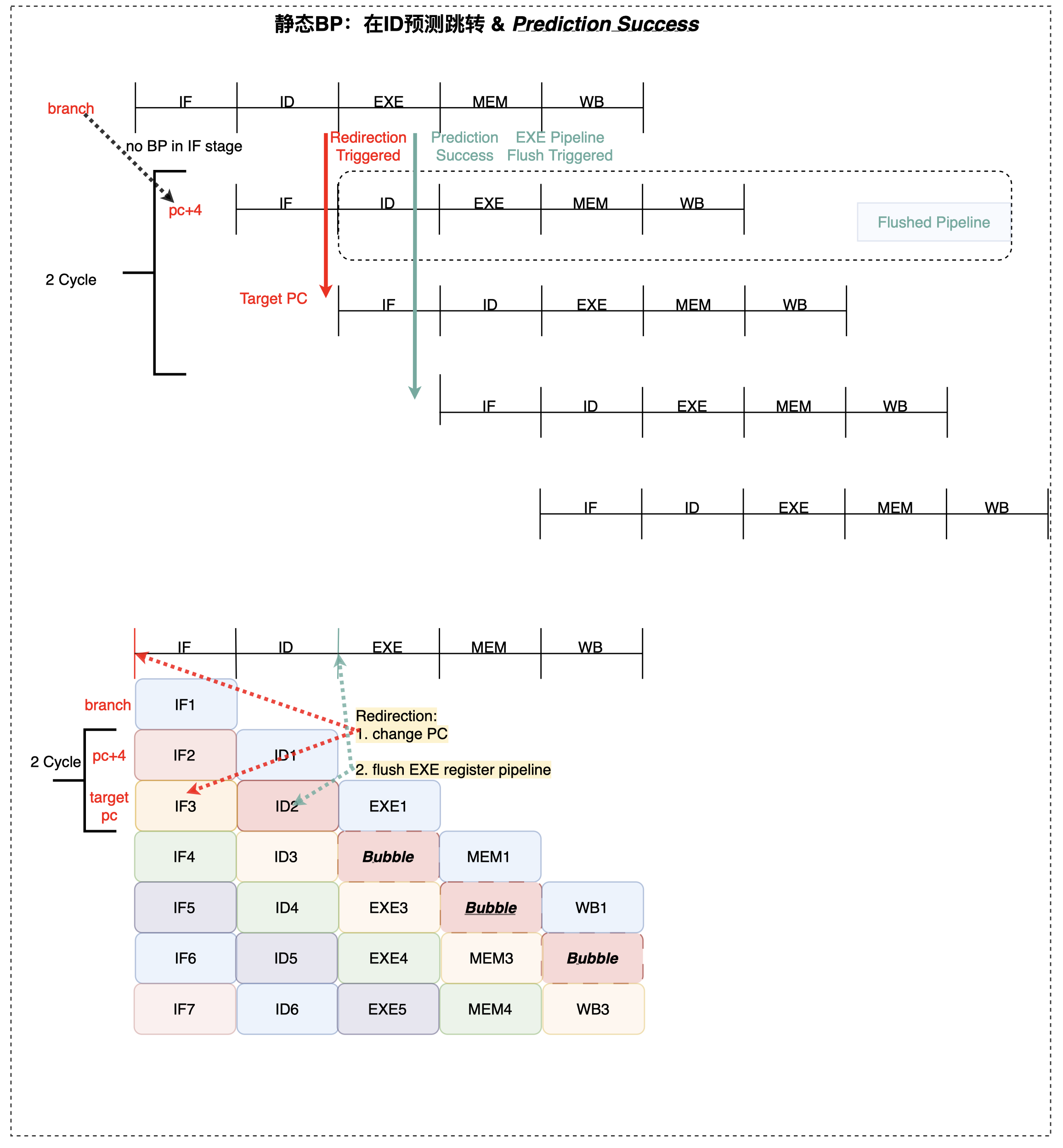
针对条件分支 B-Type 指令,其流水线有如下四种情况:
- ID 预测跳转、EXE 判断 BP 正确(实际上跳转) -> flush掉instruction
2, penalty cycle = 1
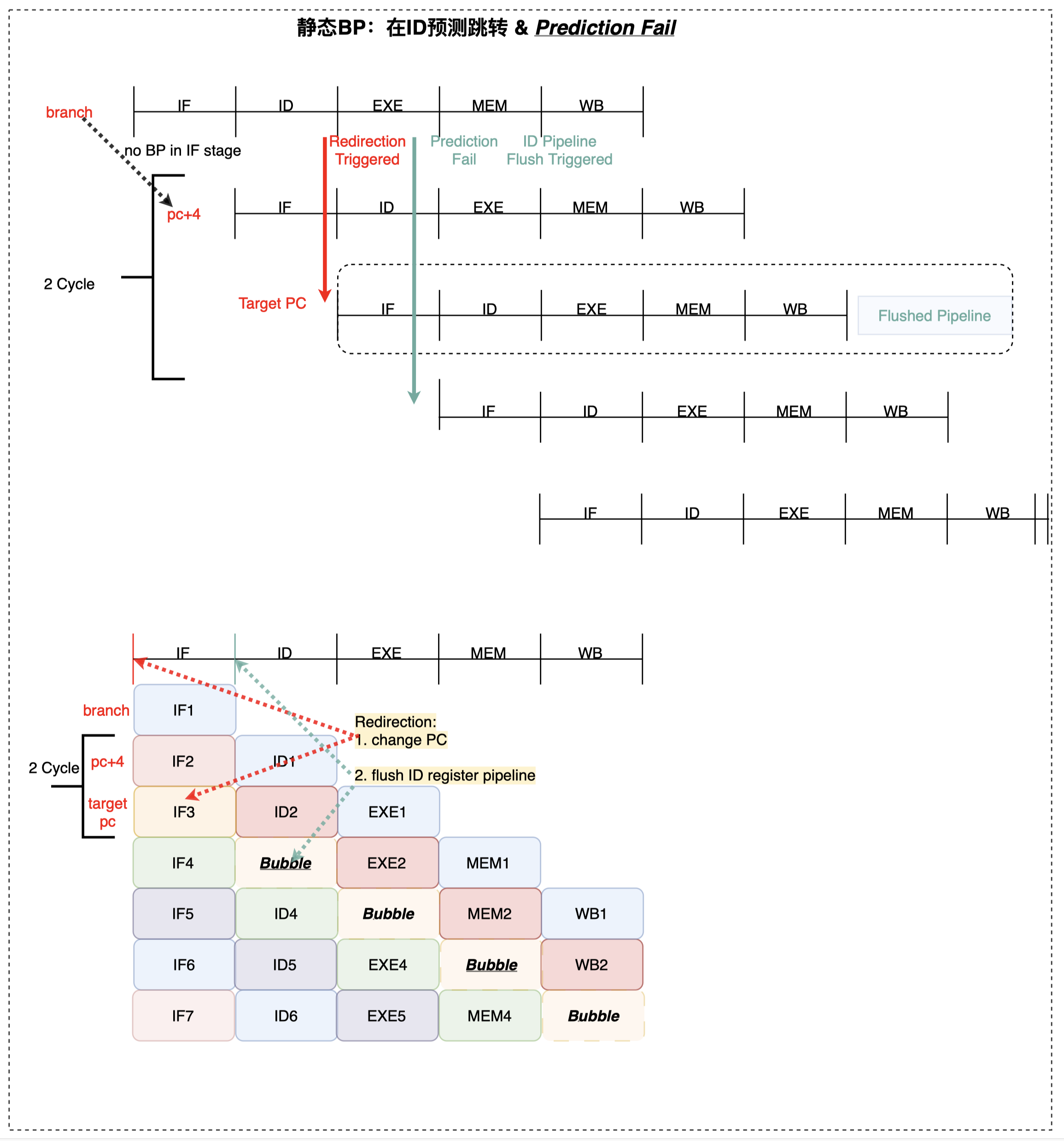
- ID 预测跳转、EXE 判断 BP 错误(实际不跳转) -> flush掉instruction
3, penalty cycle = 1
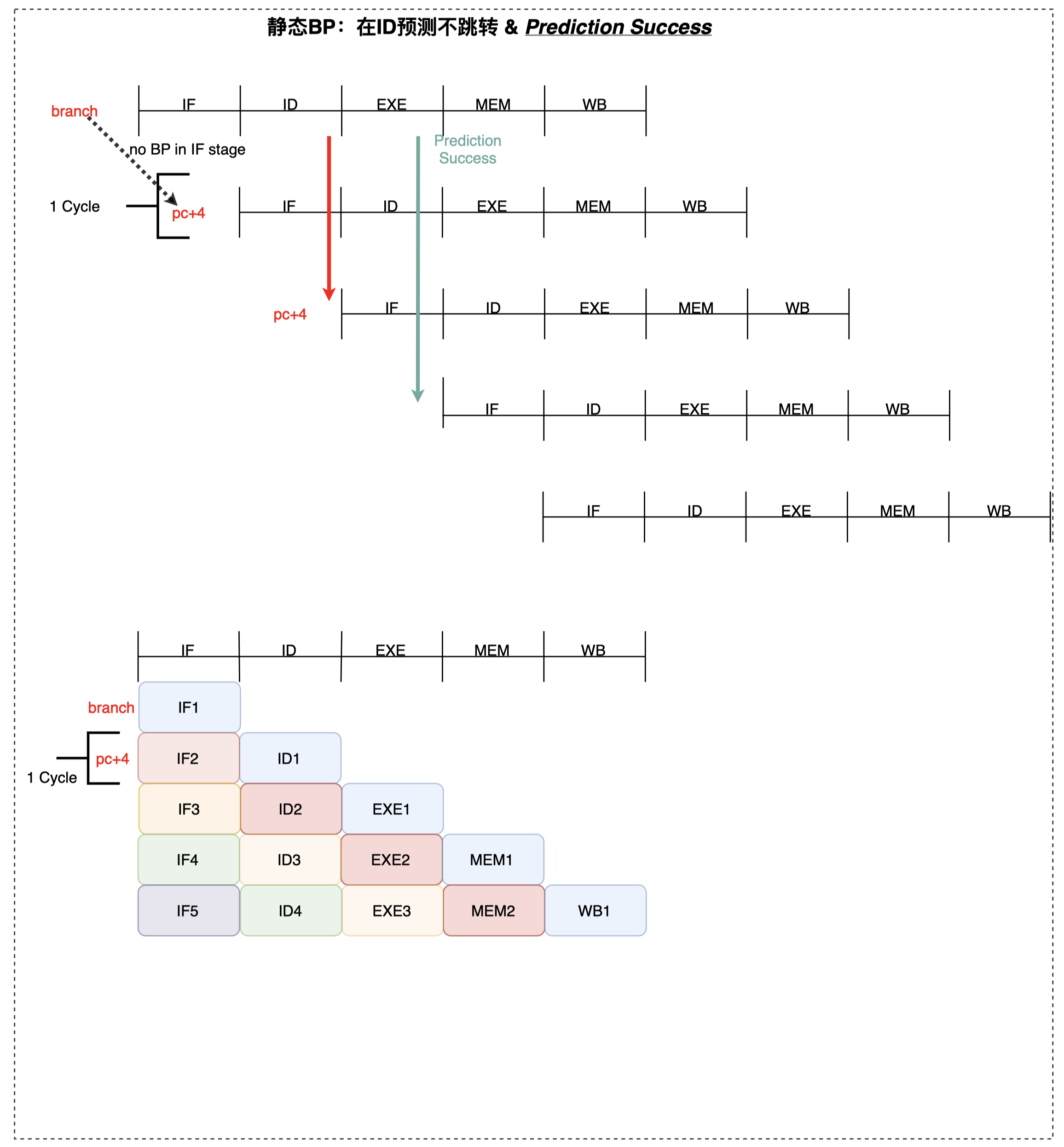
- ID 预测不跳转、EXE 判断 BP 正确(实际不跳转) -> 不用flush流水线,
penalty cycle = 0
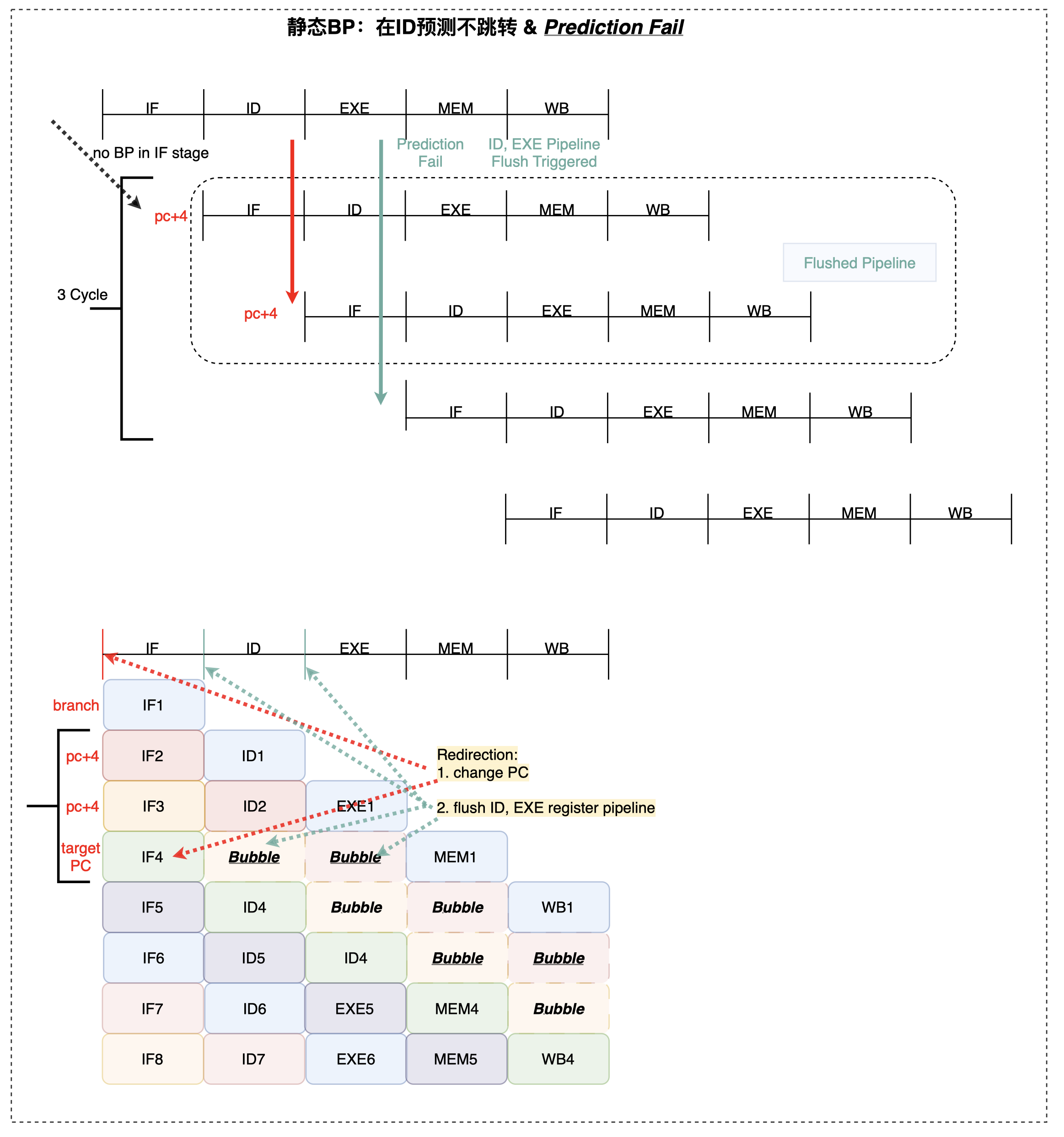
- ID 预测不跳转、EXE 判断 BP 错误(实际上跳转) -> flush掉instruction
2, 3, penalty cycle = 2
- ID 预测跳转、EXE 判断 BP 正确(实际上跳转) -> flush掉instruction
2, penalty cycle = 1
主流的分支预测器: 预测准确率和其对 CPI 的影响
准确的分支预测器 -> 减少错误预测 -> 减少 pipeline flush -> 减少 CPI
静态预测器
静态预测器不会根据指令实际执行的情况,调整其预测的结果,所有预测在程序执行之前就已经做好了
- 始终不跳转(always not token): PC+=4
- 预测准确率:~30%-40%
- 正确预测:0 misprediction penalty
- 错误预测:3 misprediction penalty(branch decision make in EXE)
- 始终跳转(always-taken)
- 预测准确率:~60%-70%
- 后向分支跳转,前向分支不跳转 BTFN(backward taken, forward not taken): 对于 B-Type 指令,如果 offset[31] 为 1,则 offset 为负, 代表其是向后分支,否则向前
动态预测器
动态预测器会根据指令实际执行的结果、历史信息来做跳转判断
一位预测器
Last time prediction(single-bit)
- 记录上次跳转的结果
- accuracy for loop = (N-2)/N
- 第一次、最后一次都会判断错误
- N(循环深度) 很大时,准确率 100%
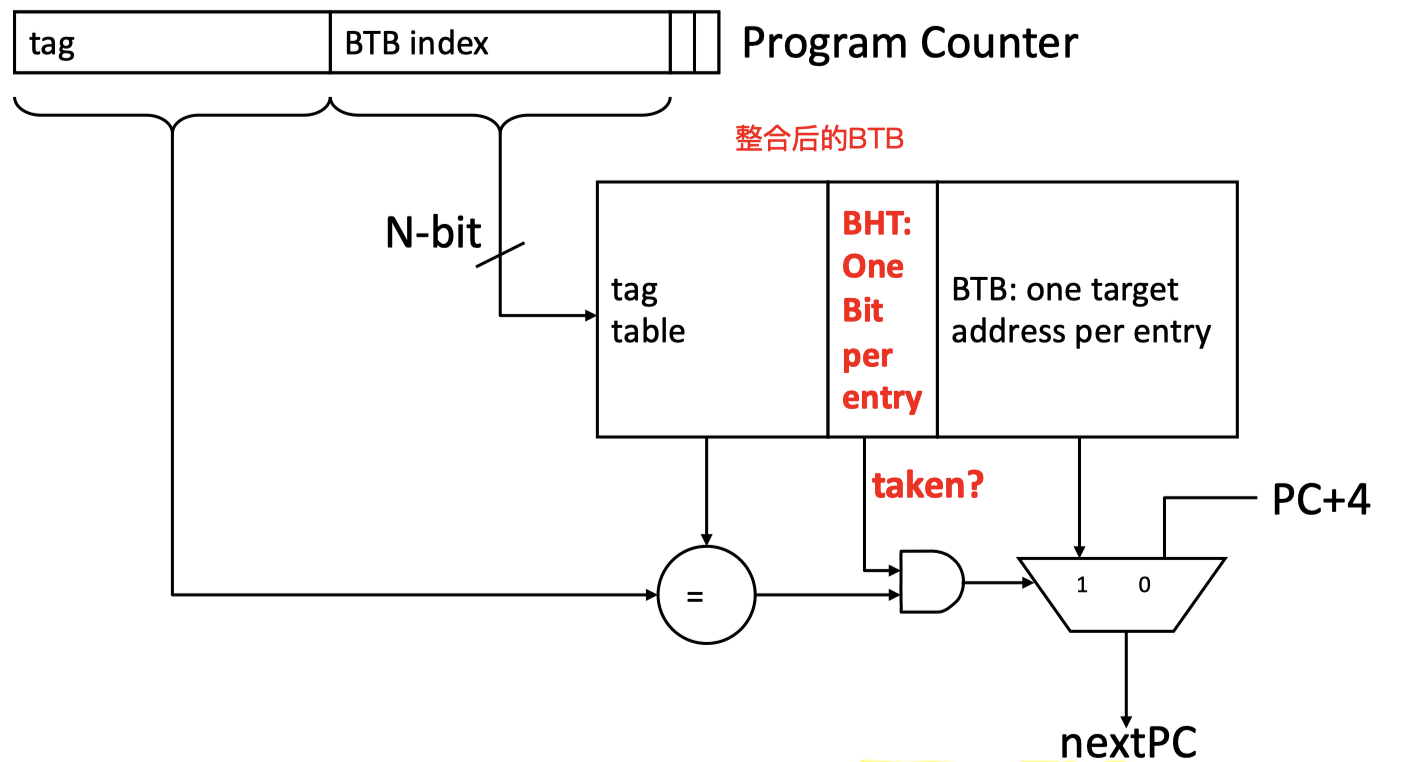
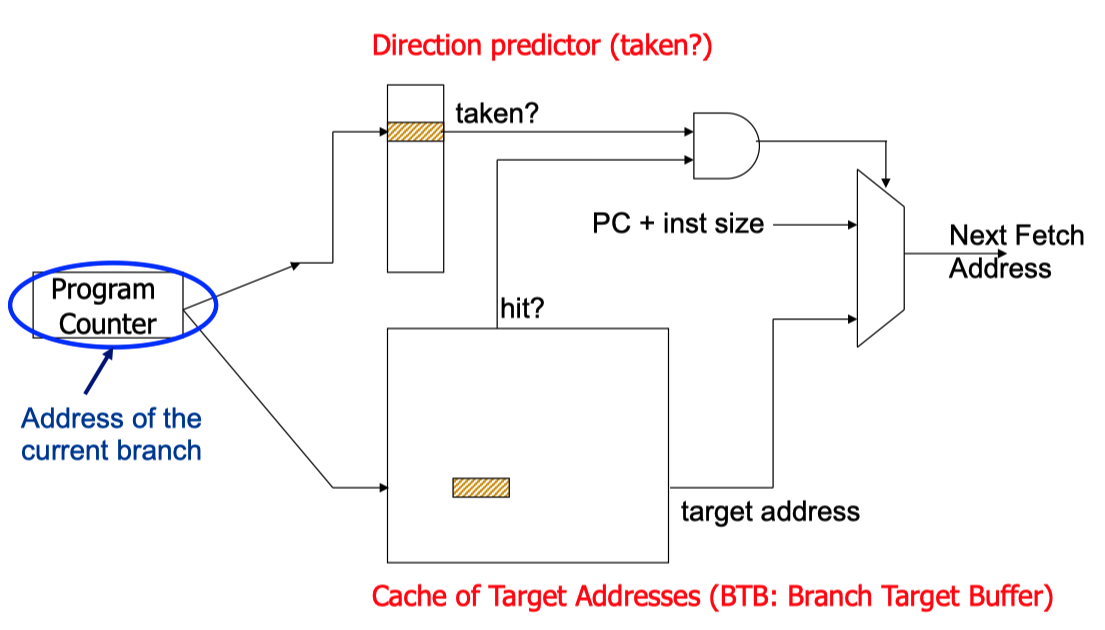
- BTB
- 对于 B-Type 指令,跳转如果发生的时候,其目的地址(target PC)是不变的,因此可以将目的地址保存到 BTB(branch target buffer)中, 这样只用判断跳转是否发生,不用计算跳转目的地址了。
- 此外,如果某个 PC 在 BTB 里有其对应的表项,则也能判断该 PC 对应一条分支指令
两位预测器(bimodal prediction)
1bit 预测器当 N 很小时,会出现震荡
- 记录上次跳转的结果,85%~90% accuracy
- accuracy for loop = (N-1)/N
- N 很小时,准确率也有 50%
更高级的动态预测器
利用全局分支历史(Global History)
可以利用其他分支指令是否跳转来提高分支预测的准确率:
1 | if(cond1) // branch 1 |
- 如果 1、2 都跳转->3 一定跳转
- 如果 1、2 有一个不跳转->3 一定不跳转
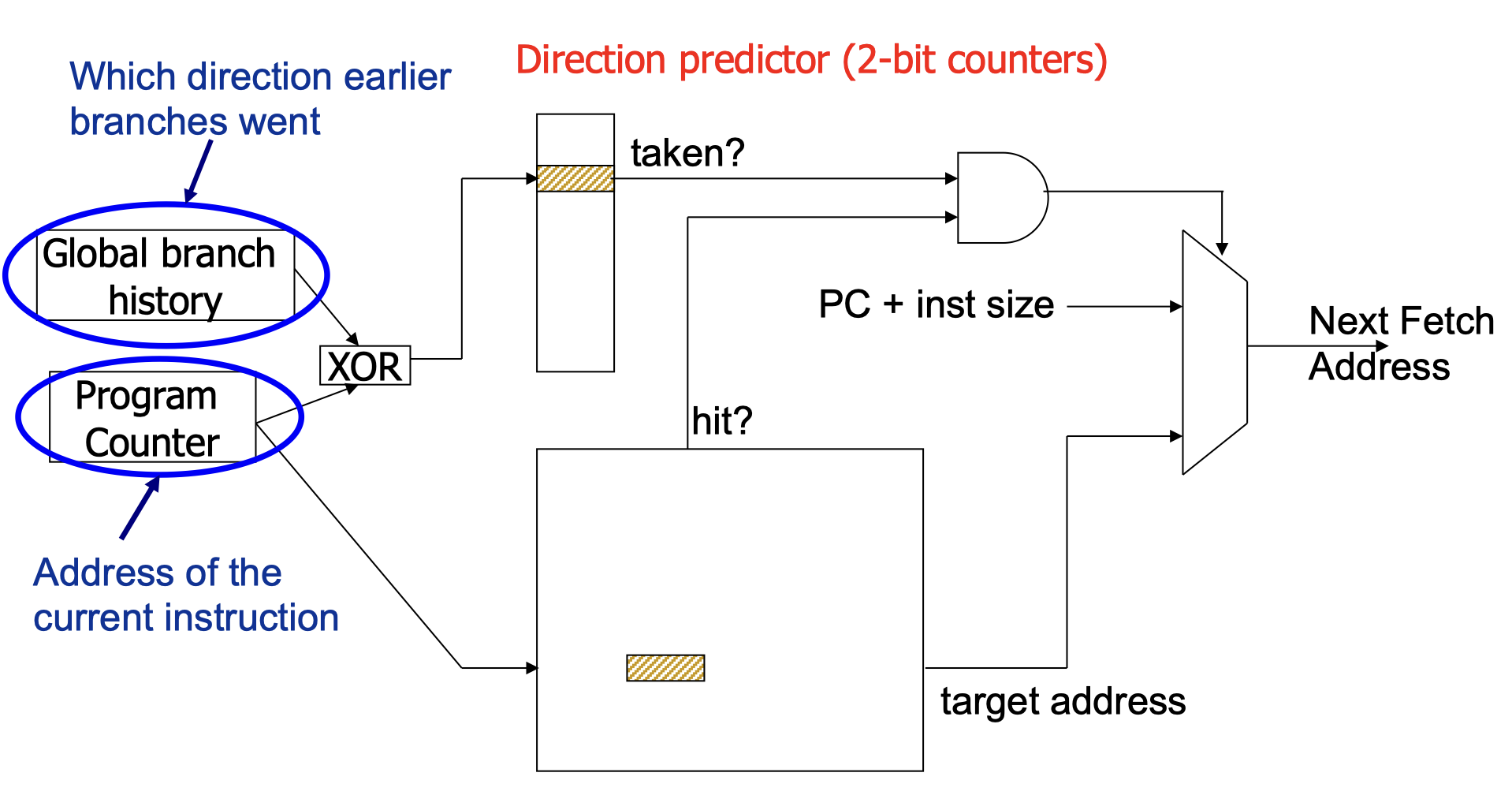
利用局部分支历史(Local History)
利用当前分支指令的前几次结果来进一步提高预测的准确率: 记录每条分支指令的历史跳转记录,用该历史跳转记录去访问 PHT(Direction Predictor),来判断是否跳转
1 | for(i=0;i<4;i++) |
记录跳转记录TTTN,则当该分支指令出现TTT之后,可以判断当前分支是不跳转
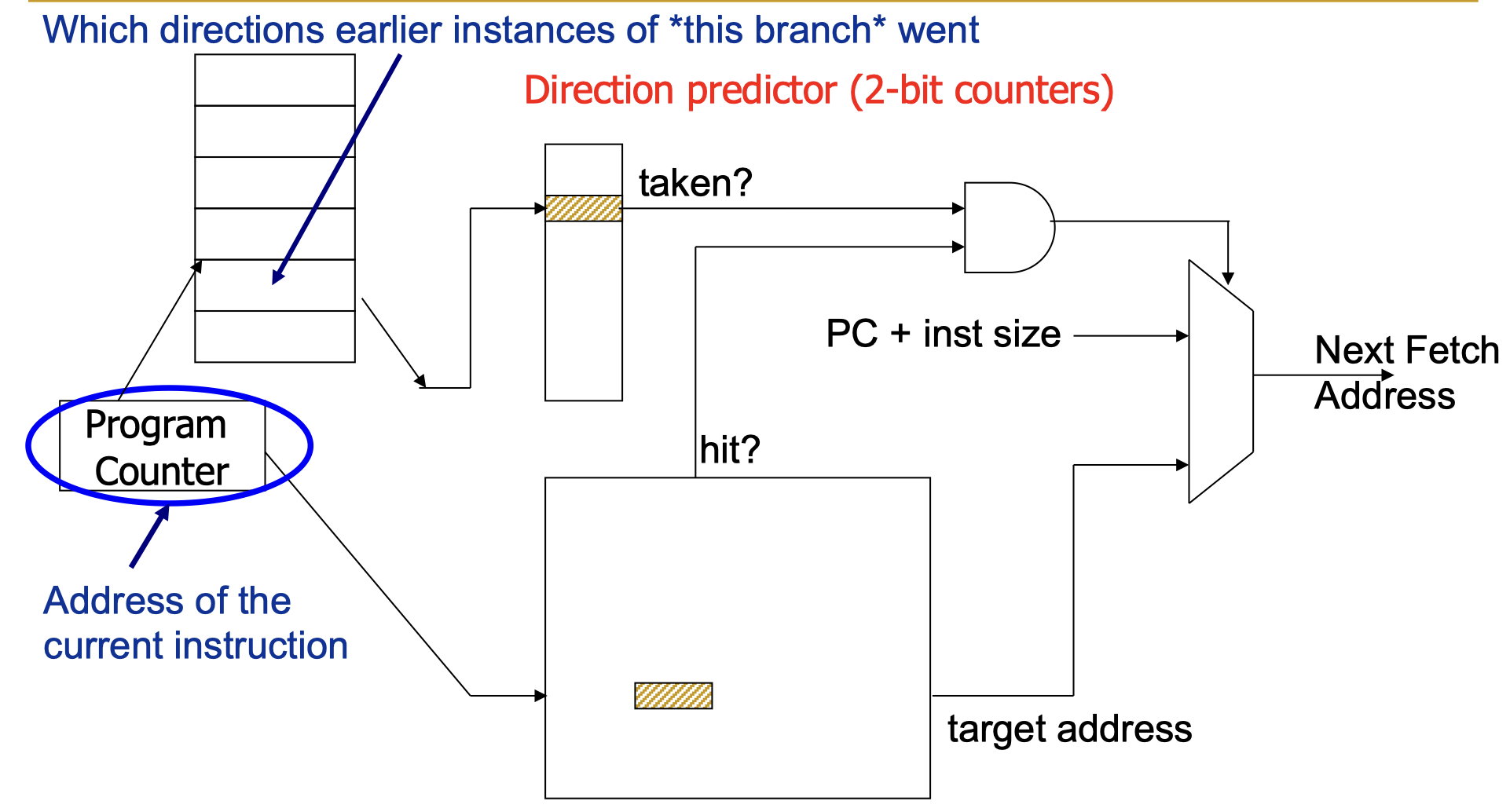
混合分支预测(hybrid branch predictor)
不同的分支指令类型适合不同的预测器:1 bit、2 bits、global branch histor、local branch history.
- 优点:准确率(90%-97%)、更短的 warmup time
- 缺点:需要选择预测器、更长的访问延迟
TAGE
TAGE (Tagged Geometric History Branch Predictor) was introduced in a 2006 paper.
不同类型的分支指令,需要不同长度的分支历史表来预测 -> TAGE 展示了一种方法来“针对不同的 branch 选择不同的分支历史长度进行预测”
how long should the branch history be?
- On the one hand, longer histories enable accurate predictions for some harder-to-predict branches.
- On the other hand, with a longer history, the predictor must track more branch scenarios and thus spend more time warming up, reducing accuracy for easier-to-predict branches.
This fundamental branch prediction tradeoff was the inspiration behind hybrid branch predictors which use multiple branch histories
TAGE 的优点来自于如下设计:
- entry 使用了 tag,避免了 aliasing(不同的指令映射到 PHT 中的同一个 entry,导致 entry 不具有参考性)
- 在用 useful 计数器来表示 entry 的有用程度、选择较短的 history 插入新的 entry
- 采用几何级数的历史记录,从而使得在分支预测过程中对各个预测表中的表项选择过程的粒度得到了很大的提升
What accuracy and CPI improve that a better BP can get over our simple static predictor
开源项目采用的预测器: 准确率和 CPI
果壳
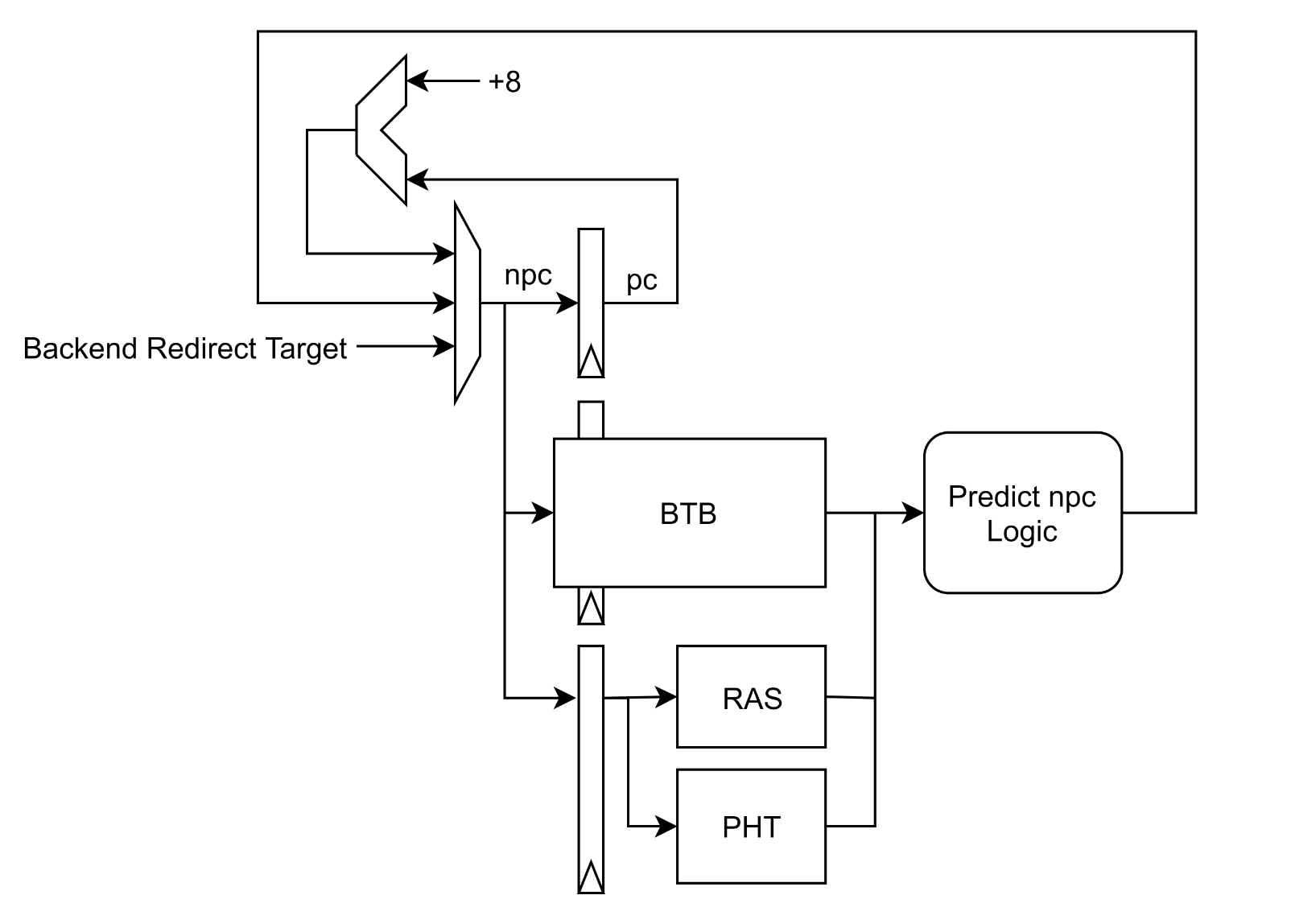 果壳的分支预测器工作工程如下:
果壳的分支预测器工作工程如下:
- 根据 PC 索引 BTB 得到 BTB 的一个表项 entry,表项的格式如下:
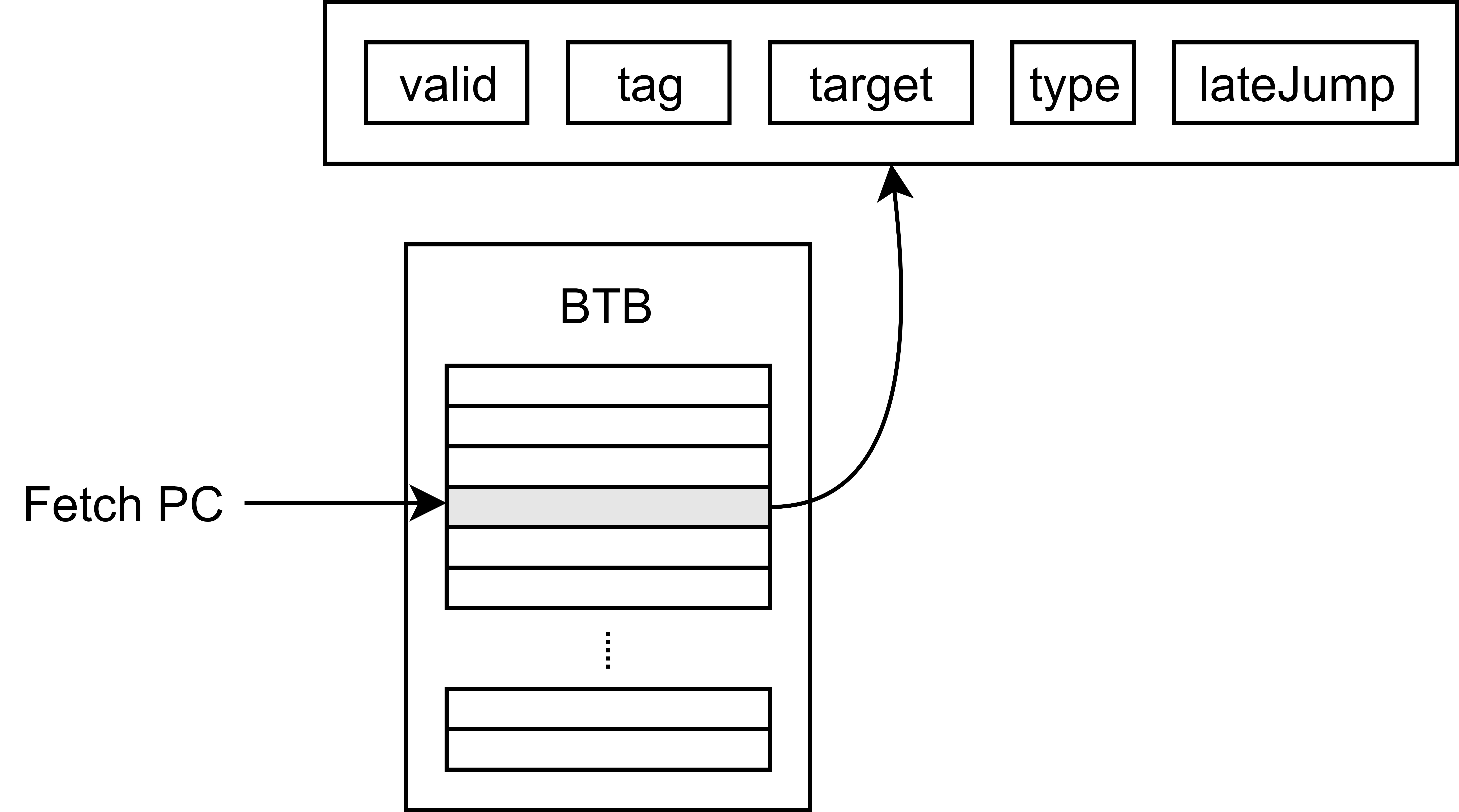
- 判断指令类型,如果是 JAL, JALR 指令,则根据表项中的 target pc 进行跳转
- 如果是 B-Type 指令,则需要根据 PHT 判断跳转与否
- 如果是 ret 指令,需要跳转到 RAS 栈顶的地址
- 分支预测器的更新:当 EXE 得到确定的分支跳转结果之后,需要返回“分支结果”和“PC”来更新分支预测器
蜂鸟 E203
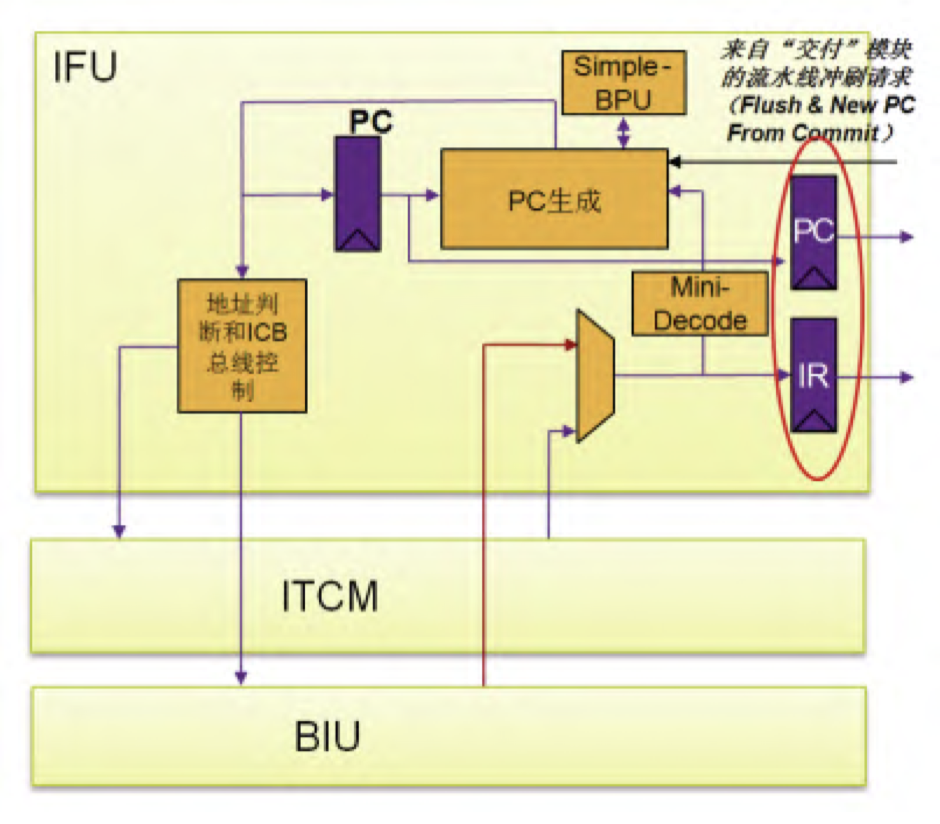 蜂鸟面向低功耗场景,它的取指过程如上图所示,其采用静态分支预测来做分支预测,预测规则如下:
蜂鸟面向低功耗场景,它的取指过程如上图所示,其采用静态分支预测来做分支预测,预测规则如下:
- 取指之后使用 mini-decode 对指令进行预译码,判断指令的类型、得到指令的立即数字段
- 对于 JAL 指令,100%跳转,计算 PC=PC+imm
- 对于 B-Type 指令,采用 BTFN 进行跳转预测, 计算跳转地址 PC=PC+imm
- 对于 JALR 指令,其 100%跳转,计算 PC 的时候需要考虑数据依赖问题,得用到 bypass 或者 stall 如果出现了数据依赖
- 静态预测器,不用更新状态
ARM M55(2021)
- pipeline 是 4cycle,分支延迟是 1 个 cycle,不需要分支预测器
- 在一些特定情况下,可以主动设置支持 LOB(low
overhead branch) extension: low overhead loops and additional branch
instructions -> 通过硬件处理 loop 地址和 loop
count,减少了
LE指令的执行
EEMBC-TeleBench
LOB performance analysis
上述基准测试主要基于循环,当引入 LOB
时,通过优化循环执行和减少分支开销来提高性能.
使用高端处理器的分支预测特性也可以获得类似的性能提升。然而,分支预测硬件通常对处理器设计有更大的面积和功耗影响.
Execution overhead cycle for the loop:
| LE (loop end) with LOB cache enabled | LE (loop end) without LOB cache enabled |
|---|---|
| 0.04% | 5.12% |
ARM A76
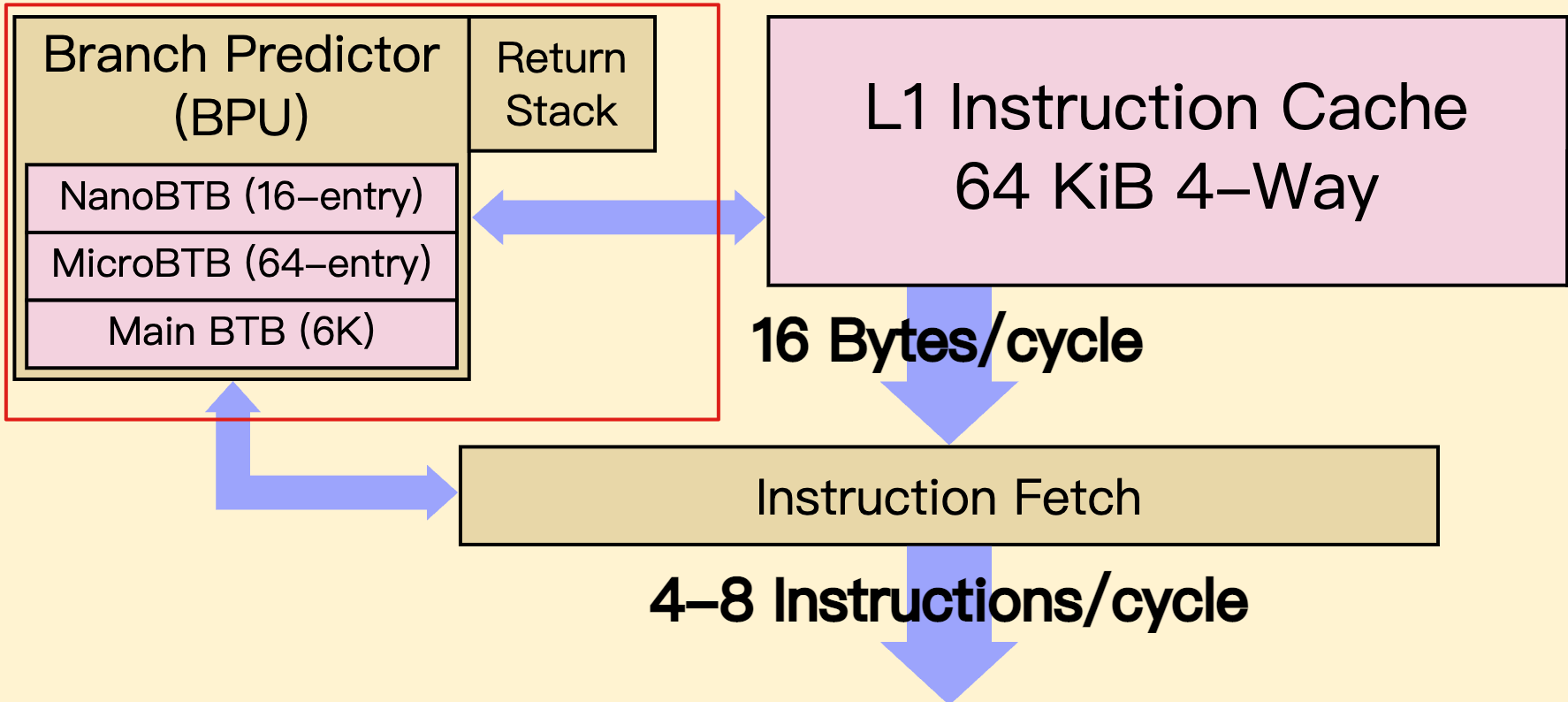
- pipeline 是 13 个 cycle,misprediction penalty 是 11 个 cycle
- 小的 BTB 返回的速度更快,大的 BTB 准确度更高
我们的设计
- 拟采用静态分支预测或者简单的动态分支预测器如(2bit
分支预测器)
- 静态分支预测:IF 需要 mini-decoder、加法器计算 target pc、JALR 的数据依赖
- 动态分支预测:BTB, PHT 的硬件消耗、EXE 得到分支结果之后对 branch predictor 的更新
- 尽管分支预测器比较简单,其预测准确率也能满足要求(不会显著增加\(CPI_{average}\))
- 流水线级数很浅,misprediction penalty 最多是 2
- 非超标量(每周期取指一条),分之判断错误需要冲刷的指令条数顶多 2 条
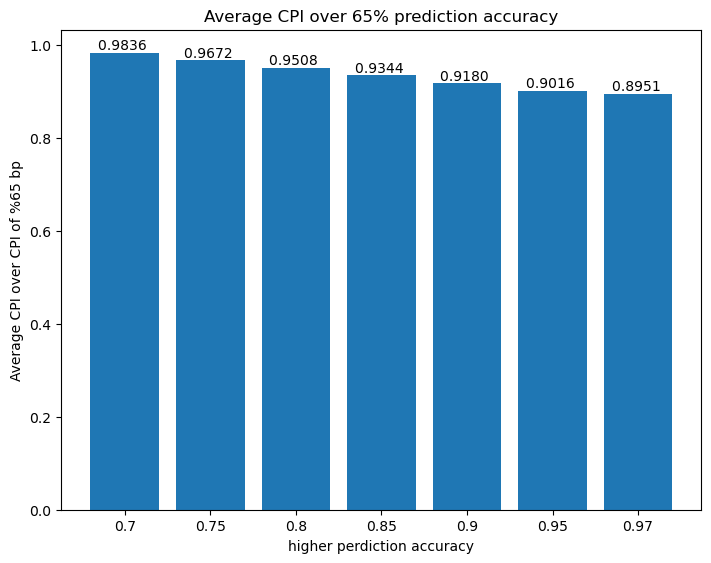
针对单发射 5 级流水线处理器,分支预测器准确率的差异(10%~20%)并不会导致 CPI 的差异很大,因此设计分支预测器时主要考虑其硬件实现的难度和对\(T_c\)的影响
分支预测器准确率对平均 CPI 的影响如下:
\[ CPI_{B}=P_B[a*1+(1-a)*penalty]=P_B*penalty+\underline{\mathbf{P_B*(1-penalty)}}*a \]
- \(P_B\):分支指令占所有指令的比重
- a: 分支预测器预测正确的概率
- penalty:分支预测器预测失败,冲刷流水线的代价
- \(CPI_B\):分支指令对平均 CPI 的贡献