Unix 环境下,RISC-V 工具链使用笔记

Unix 环境下,RISC-V 工具链使用笔记,包括如下内容:
- RISC-V 编译工具:gcc, objdump, ...
- RISC-V 调试工具:spike, pk, openOCD, GDB, llvm
- RISC-V assemble
- Verilator: 编译工具,将 Verilog 编译成 C++文件和 Makefile, 结合 C++的 testbench,可以编译成可执行的测试文件
YouTube 开源学习资料
Tool Install
RISC-V GNU Toolchain
Linux 下有 2 种方法安装编译工具链:
- 从GitHub 克隆源代码,然后按照 GitHub 中 readme 的步骤编译源代码,进行安装
- 从SiFive/freedom-tools直接下载对应平台已经编译好的可执行文件,支持
Linux/Mac/Windows 等平台
安装完成之后,可以直接在终端中看到对应的工具: 
仿真工具:spike, pk, openocd, QEMU
- Spike和QEMU都是模拟器,可以模拟 RISC-V 指令的运行
- pk 是 proxy kernel,用于在 spike 中模拟一个简单的操作系统和 bbl,这样我们才可以加载程序到 spike 中模拟运行
- openocd 是负责远程调试使用
- iverilog: 免费开源的 Verilog 仿真工具,vcs 的平替
上述工具都可以在 GitHub 中下载对应的源代码,按照 readme 中的步骤编译安装。
MacOS 下安装工具链和调试工具
macOS 下安装 riscv-gnu-toolchain,spike,pk 和 openocd 都可以直接通过 homebrew 安装:
1 | brew tap riscv-software-src/riscv |
测试是否安装成功: brew test riscv-tools,
该命令会测试工具链、riscv-isa-sim 和 riscv-pk.
总结: MacOS 下配置环境相比于 Linux 更加简单,直接使用 homebrew 就可以全部搞定。
Spike 使用
Spike 内部调试
- 进入 Spike debug:
spike --isa=rv32im -d /user/local/bin/pk hello - spike 内部 debug 命令:
until 0 pc xx: 一直运行到 pc=xx 的指令为止, 指令的地址可以搭配反汇编得到的汇编文件得到, 使用 objdumpr 1: 运行一条指令reg 0 a0: 查看 core0 中寄存器 a0 的值
使用 openOCD 远程调试
参考Debugging
with Gdb.
Spike <-> openOCD <-> GDB
Verilator 使用笔记
使用 Verilog 编写好了一个功能单元和其测试文件 testbench,如何进行仿真呢?此时可以通过 Veriloator 将其转换为 C++文件,再编译得到可执行文件,就可以运行进行仿真啦。
Verilog 的功能
对应的 alu.sv 文件和 tb_alu.cpp 文件可以在该网页中找到。
- 将 Verilog/SystemVerilog 文件转化为 C++的.h 文件和.cpp 文件以及
Makefile This converts our alu.sv source to C++ and generates build files for building the simulation executable. We use -Wall to enable all C++ errors, --trace to enable waveform tracing, -cc alu.sv to convert our alu.sv module to C++, and --exe tb_alu.cpp to tell Verilator which file is our C++ testbench.
1
verilator -Wall --trace -cc alu.sv --exe tb_alu.cpp
- 通过编译该 Makefile
可以得到可执行的文件,运行该可执行文件可以得到仿真的结果和波形
1
2make -C obj_dir -f Valu.mk Valu
./obj_dir/Valu - 打开波形 > Verilator 只有 0,1 两种状态,没有 X 和 Z 状态
1
gtkwave waveform.vcd
UVM 测试
UVM 测试是更加标准的测试,将 tb 文件分成 4 个模块:
- input driver: 负责生成 dut 的输入数据流;
input driver 的输入数据来自于 sequence generator: 负责随机地生产测试数据,用于 input driver 往 dut 里输入数据 - input monitor:负责收集输入数据流并且保存到 scoreboard
- output monitor:负责收集输出数据流并且传到 scoreboard
- scoreboard:接受 input monitor 传输到输入数据流,保存到一个队列中;收到 output monitor 的数据流时,跟队列头部保存的数据流做比较,如果匹配则一次测试通过、否则测试不通过
iverilog 使用
1 | /*adder.v*/ |
1 | /*adder_tb.v*/ |
- 编译文件:
iverilog -o <filename>.vvp <testbench-name>.v - 运行文件:
vvp <filename>.vvp - 查看波形:
gtkwave xx.vcd
总结
- 当需要快速验证一个模块的时候,可以使用 iverilog,因为它只需要编写 dut 和 tb 即可.
- 当需要验证比较大的模块的时候,还是使用 verilator+UVM 的方式,因为它虽然前期需要编写比较复杂的 c++ testbench,但是扩展性和自动化比较强。
- 此外:使用 Chisel Test 来验证 Chisel 编写的硬件模块,则更加的高级,还可以配合 difftest 使用。
- Spike 模拟器可以配合 RISC-V 汇编代码使用,当我们不了解 RISC-V 指令细节的时候,可以通过 Spike 运行对应的指令,然后查看结果。
ELF
常见的工具
- objcopy:
objcopy -O binary main.elf main.bin, copy codes from main.elf to main.bin, in binary format. - objdump: disassemble code, eg:
objdump -S main.elf, generate assemble code from main.elf - readelf: show elf file info, eg:
riscv64-unknown-elf-readelf -SW hello.o - hexdump: convert binary to hex, eg:
hexdump -C hello.bin
Difftest
两种 bug
- coding 错误:例如数组越界等
- 需求理解错误:没有正确的看手册,导致错误调试很久都不能发现
第二种错误很常见、很耗时,因此写代码和调试的时候,都要多看“手册”,避免自己误解了需求
bug 传播路径:需求->设计->代码->Fault->Error->Failure
- Fault: 有 bug 的代码,例如数组访问越界(不一定能观测到,如果不跑到该部分代码,实际上是看不到这个 bug 的)
- Error:程序运行时的非预期状态,例如错误的修改了某个内存值(不一定能观测到,如果我们不去打印这个内存值,我们也不知道这个内存被错误修改了)
- Failure:可观测的错误结果,例如输出乱码、assert 失败等(我们调试的时候,能观测到的错误,就是 Failure)
调试的过程就是从 Failure 反推,找到 Fault 的过程,二者距离越远,调试越困难。

测试
- 测试需要各种测试用例
- 单元测试:与具体模块相关,例如 decoder 模块,一般由开发者自行编写
- 集成测试:AM(abstract machine)上的各种应用,riscv-tests
- 系统测试:跑一个 RT-Thread
- 随机测试
- 好处:不用自己写测试用例
- 缺点:对于边界情况的覆盖情况不好,需要添加一些规则进行指导
- riscv-torture: 产生随机的 riscv 指令序列
- 离线程序级验证:比较程序运行得到的 signature
- 从 Failure 回溯到 Error 还是比较困难
- 若程序不能结束,则不能比较
- 测试需要各种测试用例
Difftest: 在线指令级行为验证方法
- 在线:边跑程序边验证,能够立即知道错误,从而避免错误传播成一个很难定位的 Failure
- 指令级:执行的每条指令都验证
- 优点:
- 任意程序都能进行指令级测试
- 支持不会结束的程序,例如 OS
- 无需提前知道程序的结果
调试处理器最大的挑战:如何回溯到第一次触发 Error 的指令?
想法:在每一条指令执行之后,都插入一条
assert指令,这样每条指令 如果出错,我们都可以在第一时间定位到它Q:这个 assert 指令需要检测什么东西? A:CPU 是一个巨大的状态机,我们可以检查它的:寄存器、pc、内存
Q:如何知道 CPU 的状态是否正确? A:利用 difftest,跟一个 golden model 比较
Difftest(differential testing)是来自于软件工程领域的概念, 其核心思想是:对于根据同一规范的两种实现,给定相同的输入, 它们的行为应该一致。
跟模拟器实现 difftest 的四个步骤:
- 选择一个简单的模拟器,例如:QEMU, Spike, NEMU
- 为模拟器添加如下 API:
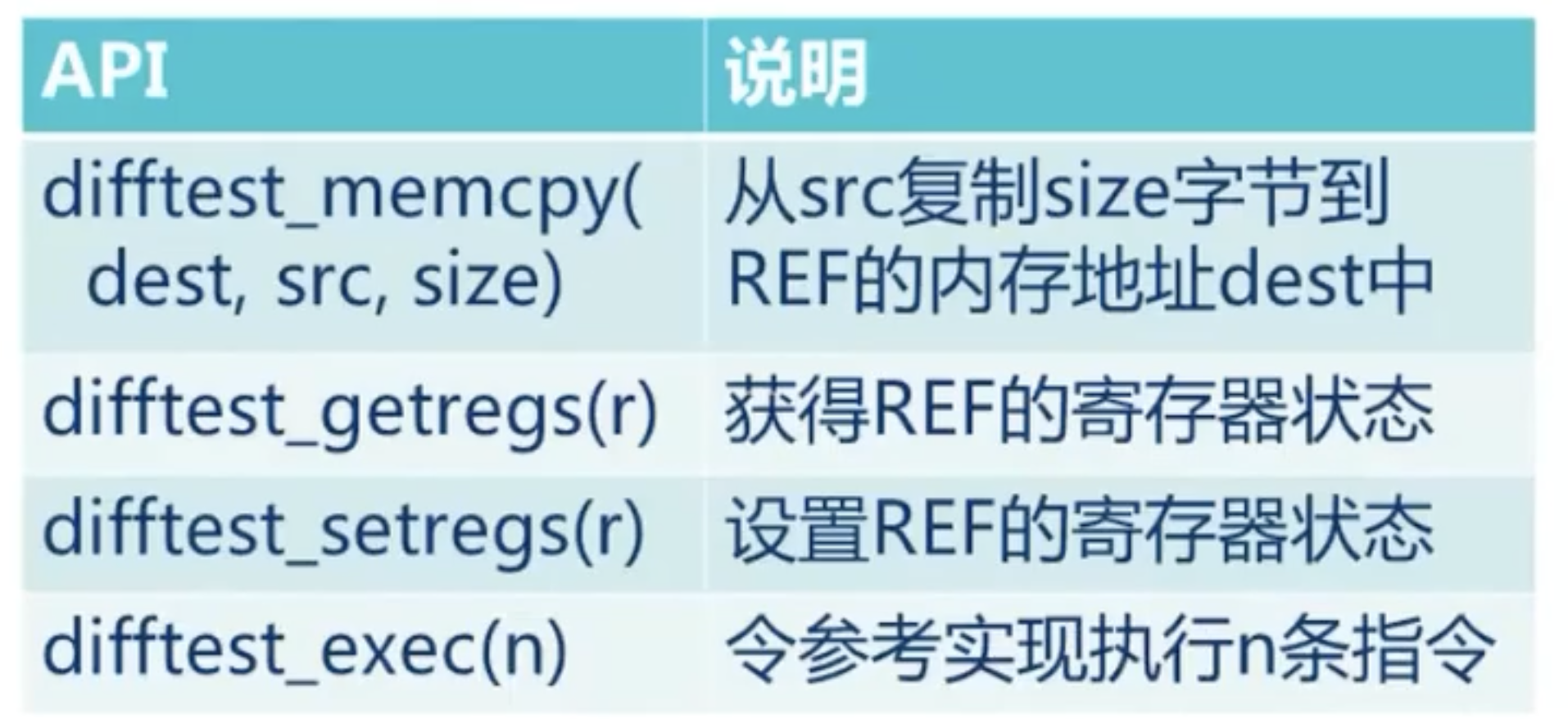
- 让仿真框架可以获得 CPU 的寄存器状态

- 在仿真框架中执行 difftest
香山中的 difftest 举例
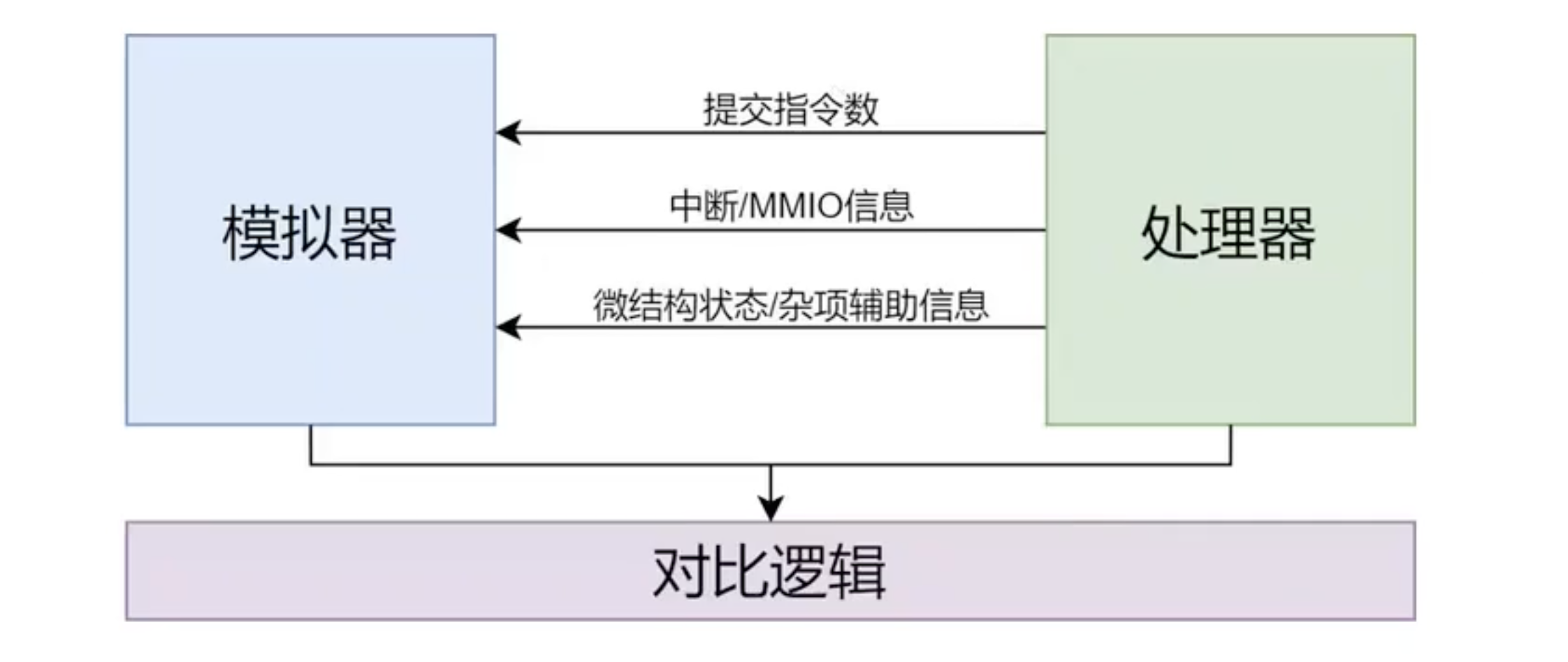
difftest 在指令提交 commit的时候进行检查
验证一条普通指令的执行
处理器将提交指令数、寄存器堆状态、pc提交给 Difftest
香山使用 DPI-C 将处理器的指令结果传递给 difftest 框架
模拟器执行相同数量的指令(一般都是 1)
比较二者的寄存器堆状态、pc
特殊情况的处理
- 模拟器无法依靠自己在一些情况上跟处理器对齐,一方面是由于模拟器跟微处理器在微架构的差异、
另一方面是因为一些外部事件无法预料
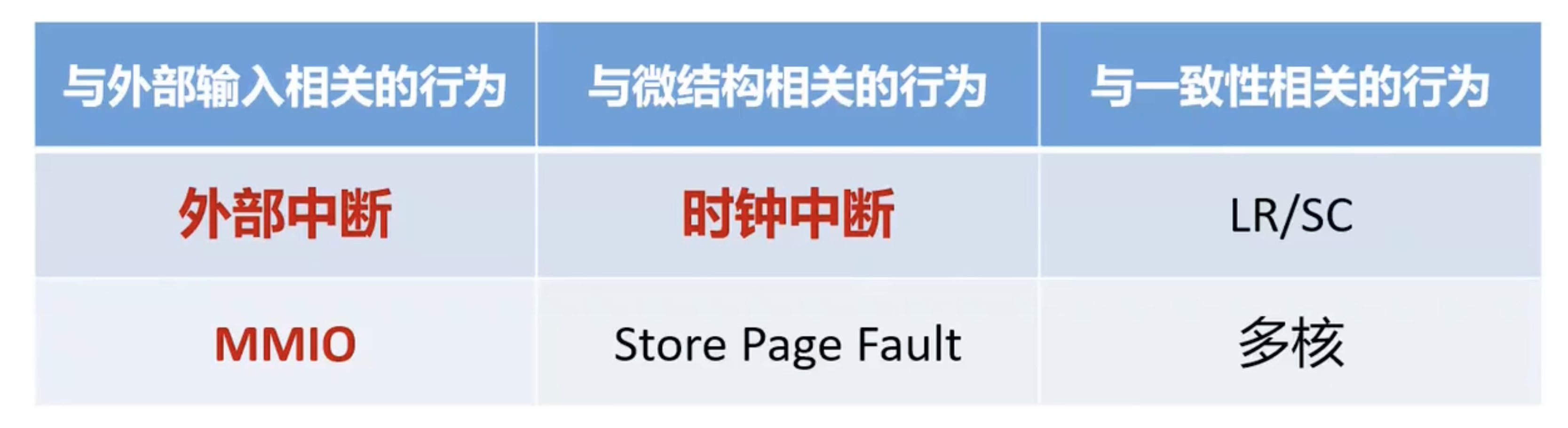
- 处理特殊情况: 处理器向模拟器传递状态,更新模拟器状态
- 在 dut 中识别特殊情况的发生
- 将 dut 的结果拷贝到模拟器中
- 跳过特殊指令的对比(difftest 中只对普通指令进行对比)
- difftest 需要处理的其他情况
- 第一条指令的情况(处理器 reset 的情况不同)
- 判断仿真终止:
- 处理器卡死
- 程序执行完成
- 处理器运行了指定的周期数
- 记录必要的信息来辅助调试
- 模拟器无法依靠自己在一些情况上跟处理器对齐,一方面是由于模拟器跟微处理器在微架构的差异、
另一方面是因为一些外部事件无法预料
香山中的 difftest 仿真框架
- 香山 difftest 框架包含一个写好的 verilator 仿真的顶层
- 用户只需要提供一个按要求修改好的 Verilog.v 文件 下面将以使用 Chisel
的设计为例,介绍如何将一个新的设计接入这个框架

- 香山的 difftest 采用DPI-C来将仿真中的信号传递到
difftest 框架中, 在仿真程序执行的时候,会调用 DPI-C 函数.
Difftest 框架提供了很多 DPI-C 函数,使用的时候可以进行选择,一般需要选择 RF, CSR, instrCommit 等子集
为什么不自行维护模拟器,而是使用通用的模拟器?
- 现如今,处理器设计时更新迭代十分的迅速,在这种情况下要维护每一版处理器微架构对应的模拟器, 一方面代码工作量很大、另一方面不满足敏捷开发的需求。
- 因此,如果要求处理器设计满足 riscv 手册的规范,我们只需要保证处理器跟模拟器在指令级层面的一致性即可, 具体表现就是每一条指令执行之后,对应的“RF, CSR, PC 和内存”都一致。