数字集成电路相关笔记
数字集成电路、芯片设计相关的笔记
[TOC]
ARM低功耗设计
参考链接
无论嵌入式系统是使用电池运行还是连接到电网,设计一个绿色且能耗最低的系统是大多数系统的共同要求。现代嵌入式系统中最大的能源消耗者之一是微控制器,了解如何将其能源消耗降至最低至关重要。
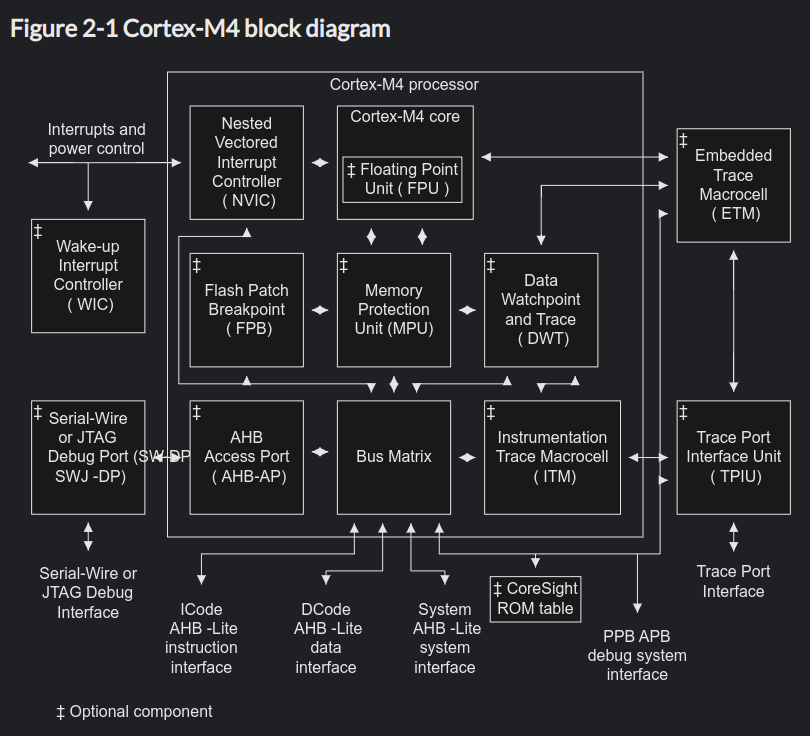
基于Arm Cortex-M处理器的每个微控制器将至少具有三种电源模式;跑步,睡觉,深度睡眠。
- 运行模式是处理器完全通电并执行嵌入式系统设计的所有操作。
- 睡眠模式将停止CPU时钟,但将使系统时钟、闪存和外围时钟保持工作状态。
- 深度睡眠模式不仅会停止CPU时钟,还会关闭系统时钟、闪存和PLL
微控制器进入睡眠状态越深,就越接近完全关闭。实现这一点很重要,因为嵌入式开发人员使用越来越深的睡眠模式时,微控制器启动和开始执行指令所需的时间可能会急剧增加。一些提供深度电源模式的处理器需要与处理器引导序列相同的时间才能再次运行。根据你的应用程序,这可能会对系统的实时性能产生重大影响。
嵌入式开发人员可以使用WFI指令将其系统置于低功耗模式,一旦触发先前配置的唤醒事件或中断,系统将立即唤醒。
Introduction
不同的并行界别
- pipeline,例如将指令分成取指、译码。。。。这些阶段;super pipeline,例如将取指再分成多个阶段,如PC计算、分支预测等
- ILP(instruction level parallel):一个周期运行多条指令(注意pipeline一个周期最多运行一条指令),常见的有“超标量superscala”、“超长自领子VLIW”
- TLP(thread level parallel):硬件执行单元被多个线程共享
- PLP(Processor lever parallel):程序在不同的处理器核上并行
不同的存储介质
- SRAM:有register构成,每个SRAM存储单元由6个transistor构成,其中有两对首尾相连的invertor,掉电丢失数据、不需要周期性刷新、集成度低、功耗大体积大、相比于DRAM(每个clock都可以读出数据)
- ROM:每个存储单元由1个transistor构成,掉电不丢失数据;Flash:后续可以写入的ROM
- DRAM:每个存储单元由1个transistor和1个capacity构成。掉电丢失数据、需要周期性刷新、相比于SRAM(集成度高、功耗较低);DDR(double Data Rate ) DRAM:在上升沿和下降沿都读取数据,提升了数据读取速度
Cache
- write-through:更新cache元素的时候,同步更新memory里面的元素、这样内存里面的值就是同步更新的。由于内存的速度更慢,所以需要使用“write buffer”,避免往内存里写数据时的等待。
- write-back:更新cache元素的时候,不写入到memory中;当cache 块被调出的时候,再写入memory中。
- victim buffer:cache替换的时候,可能刚才被替换到内存中的cache块又被需要了,如果再从内存中加载对应的块到cache中很慢,所以每次替换一个cache的时候,将其数据保存在“victim buffer”中保留一段时间,当下次如果需要的时候,可以直接从“victim buffer”中读取该cache块
- Cache的访问规则如下:将虚拟地址分成tag+index+offset。访问到时候,使用index找到对应的cache line,然后比较cache line的tag和虚拟地址的tag,如果匹配则命中,cache块命中之后,可以根据offset访问该cache块内的数据。
Cache组织方式
参考资料:Cache组织方式 by confirmwz in CSDN
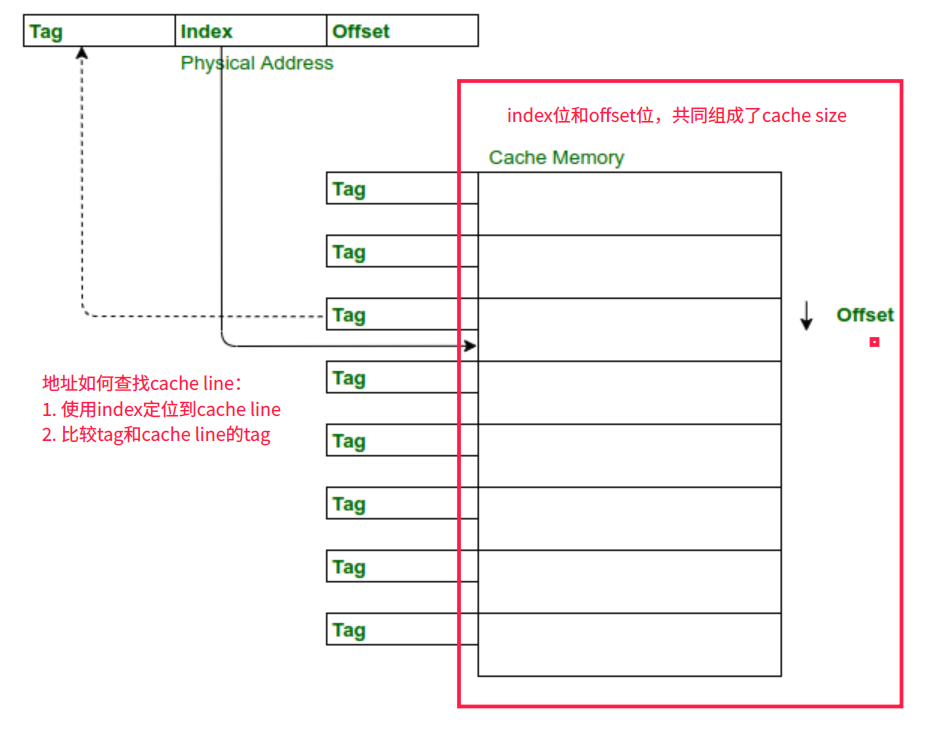
VIVT
匹配cache line的时候,tag和index都是用虚拟地址。由于存在歧义和别名,软件管理成本很高,现在基本不使用了。
- 歧义ambiguity:不同的物理地址映射到同一个虚拟地址,PS:不同的进程使用同一套的cache硬件。假设进程A的虚拟地址0x4000映射到物理地址0x2000,进程B的虚拟地址0x4000映射到物理地址0x3000。当进程A先访问虚拟地址0x4000的时候,cache miss发生,此时根据地址管理单元MMA将虚拟地址0x4000翻译得到物理地址0x2000,从物理地址0x2000取出数据,填写对应的cache line。当进程B访问虚拟地址0x4000的时候,由于使用VIVT此时cache会命中,导致发生了歧义(进程B本来要的是物理地址0x3000里的数据,结果现在从cache里读取到的是0x2000的数据)。 操作系统可以在进程切换的时候,flush掉所有的cache内容,以避免歧义的产生。
- 别名alias:相同的物理地址,映射到不同的虚拟地址,通俗点来说就是指同一个物理地址的数据被加载到不同的cacheline中就会出现别名现象。由于同一个物理地址可能映射到不同的虚拟地址,则同一个物理地址可能占用多个cache line。当不同的cache line命中时,对cache中数据的更改会导致同一个物理地址的数据不一致。
歧义和别名都是从物理地址的角度出发考虑的,其中虚拟地址的tag导致了歧义、虚拟地址的index导致了别名。
PIPT
匹配cache line的时候,都是用物理地址作为index和tag
- 优点:由于物理地址是唯一的,则不会出现歧义和别名问题
- 缺点:硬件复杂、每次都需要将虚拟地址翻译成物理地址之后再去匹配cache line
在PIPT的架构中,一般会使用TLB存储虚拟地址到物理地址的映射关系,从而避免每次地址翻译都需要访问内存。
VIPT
匹配cache line的时候,使用虚拟地址的index,使用物理地址的tag
优点:匹配cache line的时候,不用等到地址翻译完成,可以直接使用虚拟地址的index去匹配cache line;匹配cache line的同时,进行地址翻译得到物理地址,再使用物理地址作为tag,避免了歧义的发生。
是否有别名?
- 当cache的size小于页的size(4kB)的时候,不会出现别名问题。因为虚拟地址映射到物理地址的时候,其低12bit一定是一样的
- 当cache的size小于4kB的时候,VIPT等于PIPT;当cache size大于4kB的时候,虚拟地址按照cache size对齐(物理地址不会映射到指向两个cache line的两个虚拟地址),也没有别名问题。
否则将会出现别名问题,需要操作系统通过软件解决别名问题
PIVT
不存在这种cache组织方式,该方式光有缺点,没有优点。
虚拟内存
页表:存储虚拟地址到物理地址的映射方式,页表第一项是tag,第二项是页内偏移。在risc-v中地址规定如下
- 虚拟地址39位有效,其中高27位作为tag(使用tag可以匹配页表中的一项)、低12位作为页内偏移(页大小固定位4096);物理地址56位,其中高44位是物理页号、低12位是页内偏移
risc-v中的三级页表操作:
- 将27位的tag分成9+9+9的三级偏移地址L2,L1,L0
- 最高级页表有512个条目(page table entry),页表的基地址存储在SATP寄存器中。使用L2偏移定位到一个page table entry,取出其中的物理地址,得到下一级页表的基地址
- 利用上一步取出的基地址&L1偏移,定位到中间级页表的entry,取出其中的物理地址作为基地址
- 利用上一步取出的基地址&L0偏移,定位到最低级页表的entry,取出其中的物理地址作为基地址。再加上12位的offset得到最终的物理地址
使用三级页表的有点:当程序占用空间不多的时候,其页表最小只需要3*\(2^9\)个entry;如果只使用一级页表,需要使用\(2^{27}\)个entry
TLB:将页表的一部分存储到cache中,避免每次从内存中读取页表很慢
IO
- memory-mapped IO:使用特定的地址空间当做IO设备的地址空间、使用load
- explicit input/output command:IO设备使用自己的地址空间,使用input/output当做io操作的命令
- 响应IO设备可以通过“中断”、“timer 触发”等方式